PE software architecture
Sections
Puppet Enterprise (PE) is made up of various components and services including the primary server and compilers, the Puppet agent, console services, Code Manager and r10k, orchestration services, and databases.
The following diagram shows the architecture of a typical PE installation.
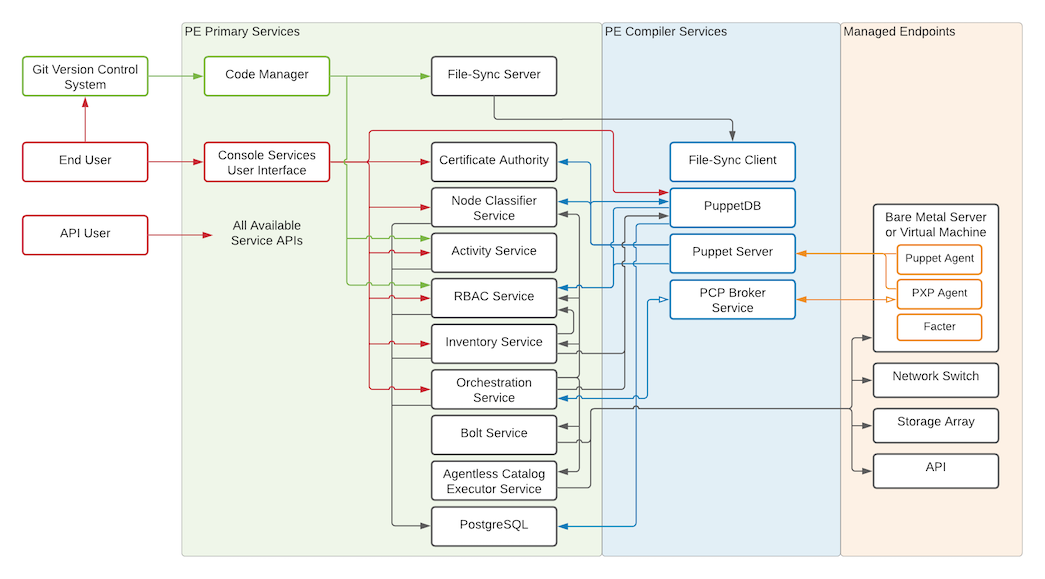
The primary server and compilers
The primary server is the central hub of activity and process in Puppet Enterprise. This is where code is compiled to create agent catalogs, and where SSL certificates are verified and signed.
PE infrastructure components are installed on a single node: the primary server. The primary server always contains a compiler and a Puppet Server. As your installation grows, you can add additional compilers to distribute the catalog compilation workload.
Each compiler contains the Puppet Server, the catalog compiler, and an instance of file sync.
Puppet Server
Puppet Server is an application that runs on the Java Virtual Machine (JVM) on the primary server. In addition to hosting endpoints for the certificate authority service, it also powers the catalog compiler, which compiles configuration catalogs for agent nodes, using Puppet code and various other data sources.
Catalog compiler
To configure a managed node, the agent uses a document called a catalog, which it downloads from the primary server or a compiler. The catalog describes the desired state for each resource that should be managed on the node, and it can specify dependency information for resources that should be managed in a certain order.
File sync
File sync keeps your code synchronized across multiple compilers. When triggered by a web endpoint, file sync takes changes from the working directory on the primary server and deploys the code to a live code directory. File sync then deploys that code to any compilers so that your code is deployed only when it's ready.
Certificate Authority
- Accepts certificate signing requests (CSRs) from nodes
- Serves certificates and a certificate revocation list (CRL) to nodes
- Accepts commands to sign or revoke certificates (optional)
.pem files in the standard ssldir
to store credentials. You can use the puppetserver ca command to interact
with these credentials, including listing, signing, and revoking certificates. The Puppet agent
Managed nodes run the Puppet agent application, usually as a background service. The primary server and any compilers also run a Puppet agent.
Periodically, the agent sends facts to a primary server and requests a catalog. The primary server compiles the catalog using several sources of information, and returns the catalog to the agent.
After it receives a catalog, the agent applies it by checking each resource the catalog describes. If it finds any resources that are not in their desired state, it makes the changes necessary to correct them. (Or, in no-op mode, it reports on what changes would have been made.)
After applying the catalog, the agent submits a report to its primary server. Reports from all the agents are stored in PuppetDB and can be accessed in the console.
Puppet agent runs on *nix and Windows systems.
Facter
Facter is the cross-platform system profiling library in Puppet. It discovers and reports per-node facts, which are available in your Puppet manifests as variables.
Before requesting a catalog, the agent uses Facter to collect system information about the machine it’s running on.
For example, the fact os returns information about the host operating
system, and networking returns the
networking information for the system. Each fact has various elements to further refine
the information being gathered. In the networking fact, networking.hostname provides the hostname of the system.
Facter ships with a built-in list of core facts, but you can build your own custom facts if necessary.
You can also use facts to determine the operational state of your nodes and even to group and classify them in the NC.
Console services
The console services includes the console, role-based access control (RBAC) and activity services, and the node classifier.
The console
The console is the web-based user interface for managing your systems.
The console can:
- browse and compare resources on your nodes in real time.
- analyze events and reports to help you visualize your infrastructure over time.
- browse inventory data and backed-up file contents from your nodes.
- group and classify nodes, and control the Puppet classes they receive in their catalogs.
- manage user access, including integration with external user directories.
The console leverages data created and collected by PE to provide insight into your infrastructure.
RBAC
In PE, you can use RBAC to manage user permissions. Permissions define what actions users can perform on designated objects.
For example:
- Can the user grant password reset tokens to other users who have forgotten their passwords?
- Can the user edit a local user's role or permissions?
- Can the user edit class parameters in a node group?
The RBAC service can connect to external LDAP directories. This means that you can create and manage users locally in PE, import users and groups from an existing directory, or do a combination of both. PE supports OpenLDAP and Active Directory.
You can interact with the RBAC and activity services through the console. Alternatively, you can use the RBAC service API and the activity service API. The activity service logs events for user roles, users, and user groups.
PE users generate tokens to authenticate their access to certain command line tools and API endpoints. Authentication tokens are used to manage access to the following PE services and tools: Puppet orchestrator, Code Manager , Node Classifier, role-based access control (RBAC), and the activity service.
Authentication tokens are tied to the permissions granted to the user through RBAC, and provide users with the appropriate access to HTTP requests.
Node classifier
PE comes with its own node classifier (NC), which is built into the console.
Classification is when you configure your managed nodes by assigning classes to them. Classes provide the Puppet code—distributed in modules—that enable you to define the function of a managed node, or apply specific settings and values to it. For example, you might want all of your managed nodes to have time synchronized across them. In this case, you would group the nodes in the NC, apply an NTP class to the group, and set a parameter on that class to point at a specific NTP server.
You can create your own classes, or you can take advantage of the many classes that have already been created by the Puppet community. Reduce the potential for new bugs and to save yourself some time by using existing classes from modules on the Forge, many of which are approved or supported by Puppet, Inc.
You can also classify nodes using the NC API.
Code Manager and r10k
PE includes tools for managing and deploying your Puppet code: Code Manager and r10k.
These tools install modules, create and maintain environments, and deploy code to your primary servers, all based on code you keep in Git. They sync the code to your primary servers, so that all your servers start running the new code at the same time, without interrupting agent runs.
Both Code Manager and r10k are built into PE, so you don't have to install anything, but you need to have a basic familiarity with Git.
Code Manager comes with a command line tool which you can use to trigger code deployments from the command line.
Orchestration services
Orchestration services is the underlying toolset that manages Puppet runs, tasks, and plans, allowing you to make on-demand changes in your infrastructure.
For example, you can use it to enforce change on the environment level without waiting for nodes to check in for regular 30-min intervals, or use it to schedule a task on target nodes once per day.
The orchestration service interacts with PuppetDB to retrieve facts about nodes. To run orchestrator jobs, users must first authenticate to Puppet Access, which verifies their user and permission profile as managed in RBAC.
Agentless Catalog Executor (ACE) service
The ACE service enables you to run Puppet jobs, like tasks and plans, on nodes that don't have a Puppet agent installed on them. ACE service primarily runs through the orchestrator but it can be configured by itself. See the PE ACE server configuration docs to configure ACE.
PE databases
PE uses PostgreSQL as a database backend. You can use an existing instance, or PE can install and manage a new one.
The PE PostgreSQL instance includes the following databases:
| Database | Description |
|---|---|
| pe-activity | Activity data from the Classifier, including who, what and when |
| pe-classifier | Classification data, all node group information |
| pe-puppetdb | Exported resources, catalogs, facts, and reports (see more, below) |
| pe-rbac | Users, permissions, and AD/LDAP info |
| pe-orchestrator | Details about job runs, users, nodes, and run results |
PuppetDB
PuppetDB collects data generated throughout your Puppet infrastructure. It enables advanced features like exported resources, and is the database from which the various components and services in PE access data. Agent run reports are stored in PuppetDB.
See the PuppetDB overview for more information.
Security and communications
The services and components in PE use a variety of communication and security protocols.
| Service/Component | Communication Protocol | Authentication | Authorization |
|---|---|---|---|
| Puppet Server | HTTPS | SSL certificate verification with Puppet CA | trapperkeeper-auth |
| Certificate Authority | HTTPS | SSL certificate verification with Puppet CA | trapperkeeper-auth |
| Puppet agent | HTTPS | SSL certificate verification with Puppet CA | n/a |
| PuppetDB | HTTPS externally, or HTTP on the loopback interface | SSL certificate verification with Puppet CA | SSL certificate allow list |
| PostgreSQL | PostgreSQL TCP, SSL for PE | SSL certificate verification with Puppet CA | SSL certificate allow list |
| Activity service | HTTPS | SSL certificate verification with Puppet CA, token authentication | RBAC user-based authorization |
| RBAC | HTTPS | SSL certificate verification with Puppet CA, token authentication | RBAC user-based authorization |
| Classifier | HTTPS | SSL certificate verification with Puppet CA, token authentication | RBAC user-based authorization |
| Console Services UI | HTTPS | Session-based authentication | RBAC user-based authorization |
| Orchestrator | HTTPS, Secure web sockets | RBAC token authentication | RBAC user-based authorization |
| PXP agent | Secure web sockets | SSL certificate verification with Puppet CA | n/a |
| PCP broker | Secure web sockets | SSL certificate verification with Puppet CA | trapperkeeper-auth |
| File sync | HTTPS | SSL certificate verification with Puppet CA | trapperkeeper-auth |
| Code Manager | HTTPS; can fetch code remotely via HTTP, HTTPS, and SSH (via Git) | RBAC token authentication; for remote module sources, HTTP(S) Basic or SSH keys | RBAC user-based authorization; for remote module sources, HTTP(S) Basic or SSH keys |
Compatible ciphers
PE is compatible with a variety of ciphers for different services.
- Puppet Server
- PuppetDB
- Console services
- Orchestrator
- Bolt Server
- ACE server
- PostgreSQL
- NGINX
These are the default TLSv1.2 and TLSv1.3 ciphers accepted by PE for FIPS and non-FIPS installations. If you use a cipher that isn't listed, it is rejected when the service is establishing a connection.
| Ciphers in IANA format | Ciphers in OpenSSL format | TLS 1.3 non-FIPS | TLS 1.3 FIPS | TLS 1.2 non-FIPS | TLS 1.2 FIPS |
|---|---|---|---|---|---|
| TLS_AES_256_GCM_SHA384 | TLS_AES_256_GCM_SHA384 | ✓ | ✓ | ||
| TLS_AES_128_GCM_SHA256 | TLS_AES_128_GCM_SHA256 | ✓ | ✓ | ||
| TLS_CHACHA20_POLY1305_SHA256
Note: Bolt server, ACE server, and
NGINX only
|
TLS_CHACHA20_POLY1305_SHA256
Note: Bolt server, ACE server, and
NGINX only
|
✓ | |||
| ECDHE-ECDSA-CHACHA20-POLY1305
Note: NGINX only
|
✓ | ||||
| ECDHE-RSA-CHACHA20-POLY1305
Note: NGINX only
|
✓ | ||||
| TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 | ECDHE-ECDSA-AES128-GCM-SHA256 | ✓ | ✓ | ||
| TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 | ECDHE-ECDSA-AES256-GCM-SHA384 | ✓ | ✓ | ||
| TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 | ECDHE-RSA-AES128-GCM-SHA256 | ✓ | ✓ | ||
| TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 | ECDHE-RSA-AES256-GCM-SHA384 | ✓ | ✓ | ||
| TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 | DHE-RSA-AES256-GCM-SHA384 | ✓ | |||
| TLS_DHE_RSA_WITH_AES_128_GCM_SHA256 | DHE-RSA-AES128-GCM-SHA256 | ✓ |