Using the feature branch workflow
Use the feature branch workflow to safely and efficiently move new code from an isolated development environment, through initial testing and validation, and then into your organization's process for staging, review, and promotion to production. Adapt the steps of this Continuous Delivery for Puppet Enterprise (PE) workflow as needed for your team's requirements and best practices.
Workflow phase 1: Develop and test code changes
The first phase of the feature branch workflow involves writing new code in a feature branch, then testing and validating that code.
- Use commits as a pipeline trigger.
- Contain a deployment that uses the feature branch deployment policy.
- (Strongly recommended) Include jobs that perform syntax validation tests before the pipeline's deployment stage.
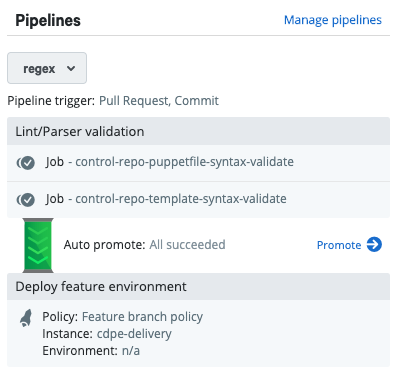
This is the same pipeline formatted as code:
pipelines:
/feature_.*/:
triggers:
- "PULL_REQUEST"
- "COMMIT"
stages:
- name: "Lint/Parser validation"
steps:
- type: "JOB"
name: "control-repo-puppetfile-syntax-validate"
concurrent_compilations: 0
all_deployments: false
- type: "JOB"
name: "control-repo-template-syntax-validate"
concurrent_compilations: 0
all_deployments: false
auto_promote: "all_succeeded"
- name: "Deploy feature environment"
steps:
- type: "DEPLOYMENT"
name: "Feature branch deployment on cdpe-delivery"
policy:
name: "cd4pe_deployments::feature_branch"
concurrent_compilations: 0
all_deployments: false
pe_server: "cdpe-delivery"
auto_promote: falseWorkflow phase 2: Review and merge to production
In the second phase of the feature branch workflow, new code is reviewed, merged into the main branch, and deployed to production. Along the way, Continuous Delivery for Puppet Enterprise (PE) provides checks and safeguards to ensure new code is only sent to production nodes after being fully vetted.
- Uses pull requests as a pipeline trigger.
- Includes a pull request (PR) gate.