Blog
July 20, 2021

If there's one thing we've learned from producing the State of DevOps Report for so long, it's how quickly the world of DevOps changes. DevOps trends can be impacted by something as specific as the tools organizations use or as complex as how they integrate it into their work approach. The point is that keeping up with DevOps takes more than following a list of best practices – it also means seeing how the development world responds and reacts to trends in the space.
That's what led us to create the State of DevOps Report in the first place. Every year, we try to bring a new perspective to the DevOps conversation based on what we’re observing in the field, backed by data and statistical analysis. With that said, here's an overview of the trends driving DevOps in 2021.
Back to topWhat Are the Current Trends in DevOps?
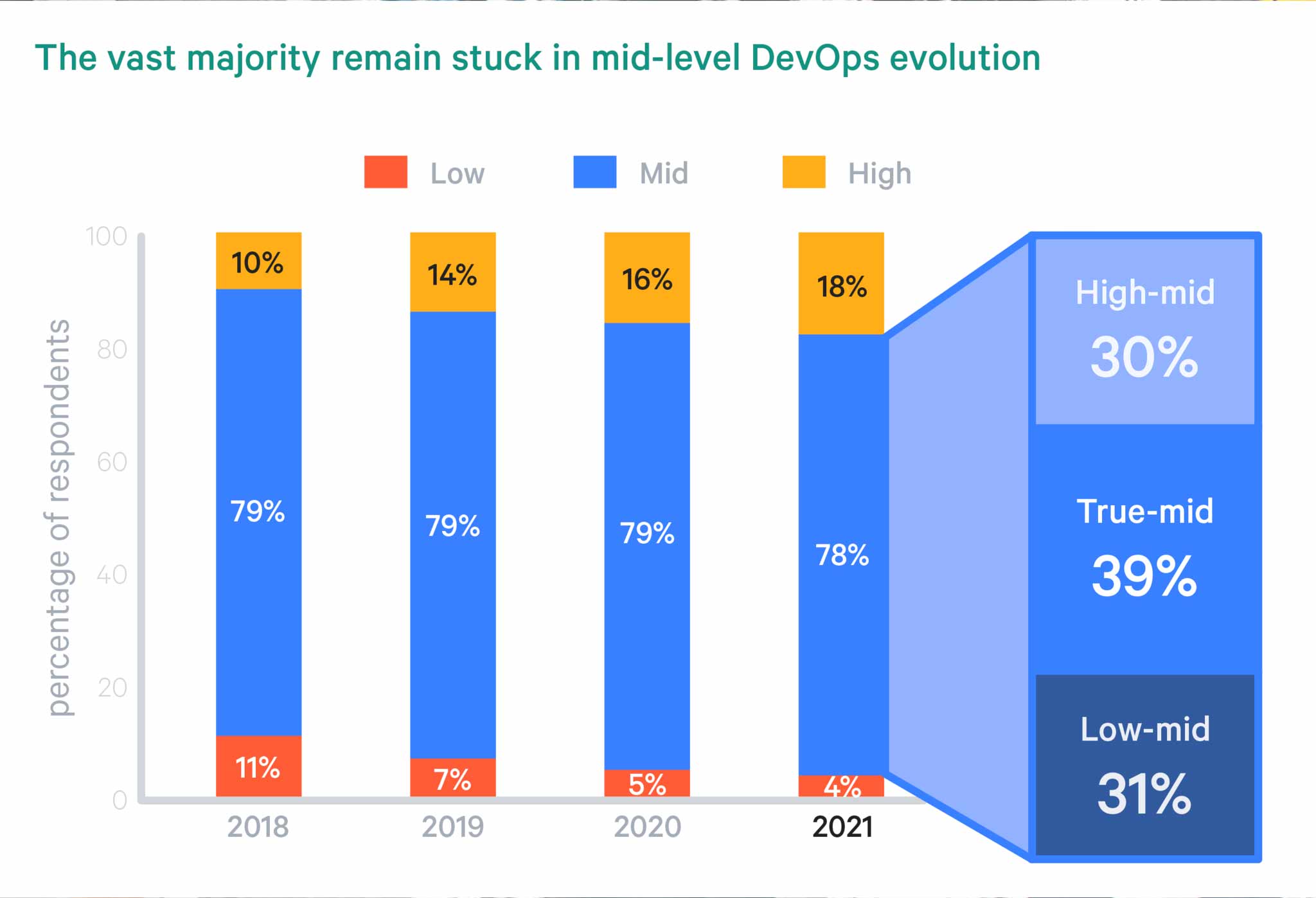
Our research of DevOps trends in 2021 uncovered a few interesting facts.
- Most organizations are stuck in the middle of adopting DevOps.
- DevOps teams need to understand their responsibilities or they'll stagnate.
- The vast majority of advanced DevOps teams use some kind of code to automate tasks.
In 2021, we set out to explore why so many firms seemed to be stuck in the middle of their DevOps evolution, the role of team identities and interaction models, and whether the rise of automation and cloud relate to an organization’s success in its DevOps evolution. (I’ll share a bit about what we’ve learned, but I highly recommend you download the report and give it a read for yourself!)
Back to topTop DevOps Trends for 2021
DevOps Trend #1: Cultural Blockers are Keeping Mid-Evolution Firms Stuck in the Middle
I admit I was not surprised to find that cultural blockers are largely at fault for keeping organizations stuck in the middle of their DevOps evolution. The most highly evolved firms benefit from top-down enablement of bottom-up transformation. That means culture. Fewer than two percent of high-evolution organizations report resistance to DevOps from the executive level, and 18% report they have no cultural blockers.
While challenges related to culture are most acute among low-evolution organizations, there are persistent blockers among mid-evolution firms. Among mid-evolution firms, a mix of cultural blockers present themselves. 21% report their culture discourages risk and 20% state responsibilities are unclear. 18% report fast flow optimization is not a priority, while 17% cite insufficient feedback loops.
DevOps Trend #2: Team Identities and Clear Interaction Paradigms Matter
So what happens when responsibilities are unclear? Enterprises are held back from evolving, thanks to cracks within organizational structure and dynamics. 91% of highly evolved teams report a clear understanding of their responsibilities to other teams compared to only 46% of low-evolution teams. While more than 3/4 of highly evolved teams state that teams adjacent to their own team have a clear understanding of their responsibilities as they relate to their own team, only 1/3 of low-evolution teams claim the same.
Highly evolved firms employ the Team Topologies model; they use a combination of stream-aligned teams and platform teams as the most effective way to manage team cognitive load at scale, and they have a small number of team types whose role and responsibilities are clearly understood by their adjacent teams. Having teams like this –and naming teams like this – creates a more well-defined path to achieving DevOps success at scale. It’s my personal opinion that ambiguous titles like a “DevOps team” provide a false sense of accuracy to many organizations who are not actually doing DevOps well.
DevOps Trend #3: DevOps ≠ Automation, DevOps ≠ the Cloud
Being good at automation does not make you good at DevOps; however, highly evolved firms are far more likely to have implemented extensive and pervasive automation. In fact, 90% of respondents with highly evolved DevOps practices report their team has automated most repetitive tasks. (Only 62% of organizations stuck in mid-evolution report high levels of automation.)
A huge number of organizations are using DevOps in the cloud, but only highly evolved DevOps teams are using it well. Organizations should not expect to become highly evolved just because they use cloud and automation. While I am the first to shout that cloud and automation are important, organizations also need to address organizational and team aspects, namely helping teams clarify their mission, primary customers, interfaces, and what makes for healthy interactions with others.
Back to topRead the 2021 DevOps Trends Report
It’s the tenth anniversary of the State of DevOps Report, and nearly 40,000 technical professionals from around the world have contributed to this body of research, the longest-running and most widely referenced DevOps research in the industry.
To observe the ten year anniversary of the report, Puppet invited a wider group of DevOps influencers to respond to the data. Contributors include the authors of the Team Topologies model, which has been immensely influential in the industry, as well as DevOps luminaries like Charity Majors, Patrick Debois, Stephen Thair, and many others. I’m immensely grateful that they took the time to interact with this year’s data and share their expertise with such a wide audience.
We also want to thank all 2,650+ people who took the time to complete our survey. For every individual who took the 2021 State of DevOps survey, we donated $5 to the National Coalition for the Homeless, the World Central Kitchen, and the UNICEF COVID-19 Solidarity Response Fund. We donated additional funds, provided by our generous sponsors, bringing our total contribution to $45,000. A huge thanks to our sponsors—Armory, BMC, Bridgecrew, Continuous Delivery Foundation, New Relic, ServiceNow, Snyk, Splunk, Team Topologies, and Women in DevOps.
I don’t want to give too much away, as there is so much more to this year’s State of DevOps Report. We build on last year’s findings around the benefits of a platform team, discuss how DevOps success includes stronger security, and much more. Our hope is these findings help you identify where in your DevOps evolution your company is, and we provide recommendations for achieving that future state of DevOps. We hope you enjoy reading the report as much as we enjoyed researching and writing it.
Back to topLearn More
- What is DevOps? Get familiar with this comprehensive overview of DevOps.
- Read our guide on getting started with DevOps
- The DevOps KPIs that organizations care about most
- How HelloFresh does developer happiness
- How to build your DevOps foundation like high-performing organizations do
- Read ten years' worth of DevOps research in our History of DevOps Reports hub.