Blog
November 15, 2020

Did you know that there's a Puppet Enterprise plugin for Jenkins Pipeline? Find out why and how to use it.
Table of Contents:
- What Is Jenkins Pipeline?
- Why Use Puppet With Jenkins Pipeline?
- How the Puppet Enterprise for Jenkins Pipeline Plugin Works
- What’s Next For Jenkins + Puppet?
What Is Jenkins Pipeline?
Jenkins Pipeline is a collection of plugins that support continuous delivery pipelines in Jenkins.
Jenkins Pipeline introduced a world where pipelines are defined and managed from the version control repository that houses the code the pipeline delivers. Simply place the pipeline code in a file called Jenkinsfile, and keep it in your project's repository. This is a powerful idea. It means the definition of the process, which the code must follow to be delivered, lives with the project's code itself. The Jenkins Pipeline plugin means the process definition's history is recorded with the project's code history. It means any pipeline can be shared and replicated at any time.
Back to topWhy Use Puppet With Jenkins Pipeline?
Using Puppet with Jenkins Pipeline makes it easy to use Puppet to perform some or all of the deployment tasks in continuous delivery pipelines. This helps you cross the everything-as-code chasm.

Puppet users have long been managing infrastructure as code. The benefits are as enormous as they are obvious. However, managing infrastructure code in a continuous delivery pipeline has been a practice for the Puppet elite.
Direct, deliberate, and orchestrated control of Puppet agent runs from tools like Jenkins have been difficult to accomplish, to say the least. Existing practices are complex, brittle, and difficult to maintain. So we had a world where both holistic continuous delivery pipelines and entire global infrastructures could be managed as code — yet there was no obvious way to merge these two worlds. There is a chasm between them.
The Puppet Enterprise plugin for Jenkins Pipeline solves the problem by providing simple methods that can be called from a Jenkinsfile to set Hiera values, deploy Puppet code to the Puppet servers, and manage Puppet orchestration jobs. The plugin makes it trivial for pipeline code to manage infrastructure code so you can cross the everything-as-code chasm.
Back to topHow the Puppet Enterprise for Jenkins Pipeline Plugin Works
The Puppet Enterprise for Jenkins Pipeline plugin itself has zero system dependencies, making buy-in from the team that manages Jenkins simpler. You need only to install the plugin from the update center. The plugin uses APIs available in Puppet Enterprise to do its work, and is compatible with Puppet Enterprise 2015.2 and up, though many orchestration features require Puppet Enterprise 2016.4. Since the code management, node management, and orchestrator APIs are all backed by Puppet Enterprise’s role-based access control (RBAC) system, it’s easy to restrict what pipelines are allowed to control in Puppet Enterprise.
puppet.codeDeploy 'dev'
puppet.job 'dev'
stage 'Promote to staging'
input "Ready to deploy to staging?"
promote from: 'dev', to: 'staging'
stage 'Deploy to staging'
puppet.codeDeploy 'staging'
puppet.job 'staging'
stage 'Staging acceptance tests'
Authentication
The plugin uses the Jenkins built-in credentials system to store and refer RBAC tokens to Puppet Enterprise for authentication and authorization. After generating a Puppet Enterprise RBAC token, create a new Secret text credential in Jenkins and set the Secret value to the token.
In your Jenkinsfile, use the puppet.credentials method to set all future Puppet methods to use the RBAC token. For example:
puppet.credentials ‘pe-team-token’Creating an Orchestrator Job
The orchestration service in Puppet Enterprise is a powerful tool that enables orchestrated Puppet runs across as broad or as targeted an infrastructure as you need at any given time. You can use the orchestrator to update applications in an environment, or update a specific list of nodes, or update nodes across a set of nodes that match certain criteria. In each scenario, Puppet will always push distributed changes in the correct order by respecting the cross-node dependencies.
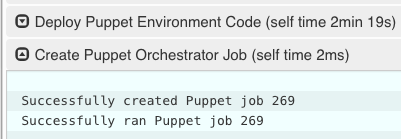
To create a job in the Puppet orchestrator from a Jenkins pipeline, use the puppet.job method. The puppet.job method will create a new orchestrator job, monitor the job for completion, and determine if any Puppet runs failed. If there were failures, the pipeline will fail.
To run Puppet against all of production:
puppet.job ‘production’To run Puppet against instances of an application in production:
puppet.job ‘production’, application: ‘Myapp’To run Puppet against nodes db.example.com, appserver01.example.com, and appserver02.example.com:
puppet.job ‘production’, nodes: [‘db.example.com’,’appserver01.example.com’,’appserver02.example.com’]To run Puppet against all Red Hat nodes in the AWS us-west-2c region that were created in the last 24 hours using a PQL query:
puppet.job ‘production’, query: ‘inventory[certname] { facts.os.name == “RedHat” and facts.ec2_metadata.placement.availability-zone = “us-west-2c” and uptime_hours < 24 }’As you can see, the puppet.job command means you can be as broad or as targeted as you need to be for different parts of your pipeline. There are many other options you can add to the puppet.job method call, such as setting the Puppet runs to noop, or giving the orchestrator a maximum concurrency limit.
🔧 See it all come together — request a demo from the Puppet team.
Updating Puppet Code
If you’re using code management in Puppet Enterprise (and you should), you can ensure that all the modules, site manifests, Hiera data, and roles and profiles are staged, synced, and ready across all your Puppet servers, direct from your Jenkins pipeline.
To update Puppet code across all Puppet servers, use the puppet.codeDeploy method.
puppet.codeDeploy ‘staging’Setting Hiera Values
The plugin includes an experimental feature to set Hiera key/value pairs. There are many cases where you need to promote information through a pipeline, such as a build version or artifact location. Doing so is very difficult in Puppet, since data promotion almost always involves changing Hiera files and committing to version control.
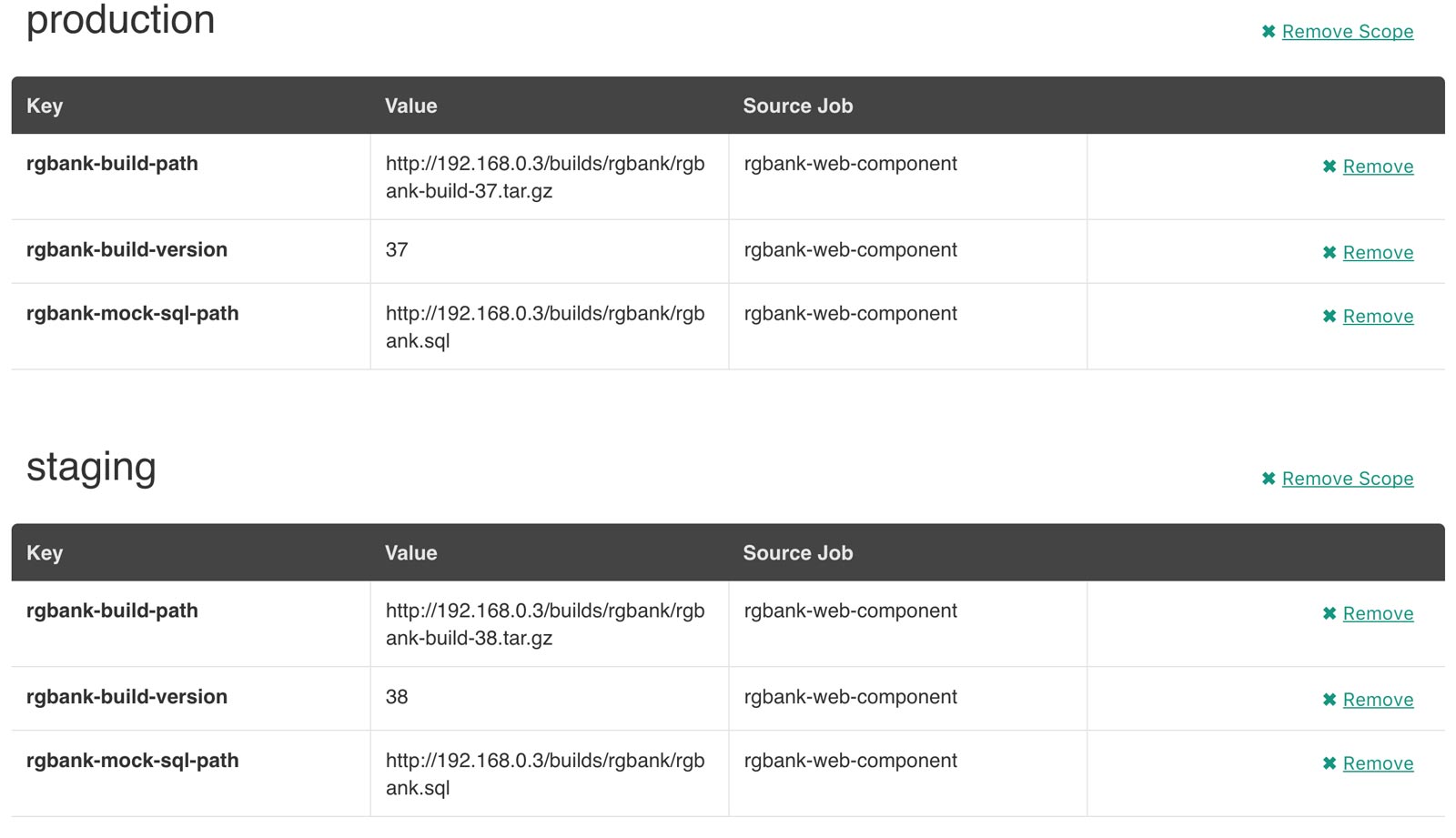
The plugin exposes an HTTP API endpoint that Hiera can query using the hiera-http backend. With the backend configured on the Puppet server(s), key/value pairs can be set to scopes. A scope is arbitrary and can be anything you like, such as a Puppet environment, a node’s certname, or the name of a Facter fact like operatingsystem or domain.
To set a Hiera value from a pipeline, use the puppet.hiera method.
puppet.hiera scope: ‘staging’, key: ‘build-version’, value: env.BUILD_IDNow you can set the same key with the same value to the production scope later in the pipeline, followed by a call to puppet.job to push the change out.
A Practical Example
Let's take a look at managing a Puppet control repository in a pipeline. As changes to Hiera data, site manifests, Puppetfiles, and roles and profiles are introduced to the control repository, they need to go through a rehearsal, which often equates to a run in staging. Next, you might want to push the change out to a few canary systems, and finally do a full run in production while containing the thundering herd with a concurrency limit.
First, create a file called Jenkinsfile in your Puppet control repository and create a pipeline job in Jenkins that uses that Jenkinsfile.
The first thing we want to do in the Jenkinsfile is set which Puppet Enterprise RBAC token should be used for calling out to Puppet Enterprise. This line specifies that the RBAC token to be used can be found in the Jenkins credential named ‘pe-access-token’.
puppet.credentials 'pe-access-token'Now that the RBAC token is loaded, let’s deploy the staging environment. The following code will create a Deploy to staging stage in the pipeline, lock the step so that no other jobs can simultaneously deploy to staging, ensure the Puppet code is deployed and synced to all the Puppet servers, and finally run a Puppet orchestration job against all nodes in the staging environment.
stage 'Deploy to staging'
lock(‘puppet-code-staging’) {
puppet.codeDeploy 'staging'
puppet.job 'staging'
}Now that any changes have been deployed to staging, you can inspect the Puppet Enterprise web UI to ensure the changes you were expecting to be deployed actually happened as expected. The next part of the pipeline will wait for approval, then promote the Puppet code changes to the Puppet production environment. The promote method is not part of the plugin. That is a helper method you can add to your Jenkinsfile to merge and push the Puppet code between Git branches. An example implementation of the promote method can be seen in this example Jenkinsfile.
stage 'Promote to production'
lock(‘puppet-code-production’) {
input "Ready to promote to production?"
promote from: 'staging', to: 'production'
puppet.codeDeploy 'production'
}Now that the production Puppet code is updated on Puppet servers, you can do a noop Puppet run in production to ensure only the expected changes would occur.
stage 'Noop production run'
lock(‘puppet-code-production’) {
puppet.job 'production', noop: true
}Use Event Inspection in the Puppet Enterprise web UI to make sure only the expected changes would occur. Next, have the pipeline wait for approval to continue. Upon approval, do Puppet runs across a subset of production nodes using a PQL query.
stage 'Deploy to production canary systems’
lock(‘puppet-code-production’) {
input "Ready to deploy to canaries?"
//Run Puppet on 10 production systems
puppet.job 'production', query: ‘inventory[certname] { environment = “production” order by certname limit 10 }’
}Finally, pause the pipeline and wait for approval to continue, then run Puppet across the entire production environment. Be sure to limit the concurrency so there aren't too many nodes requesting catalogs from the server at the same time.
stage ‘Deploy to all of production’
lock(‘puppet-code-production’) {
input “Ready to deploy to all of production?”
//Run Puppet in production, but no more
// than 20 nodes at a time
puppet.job ‘production’, concurrency: 20
}You can find more examples in the examples directory.
Back to topWhat’s Next For Jenkins + Puppet?
We’re very excited not only about what this plugin can enable for you, but where we can take it. We encourage everyone to get started with continuous delivery today, even if it’s just a simple pipeline. The benefits of continuous delivery are enormous. As your practices evolve, you can begin to add automated tests, automate away manual checkpoints, start to incorporate InfoSec tests, and include phases for practices like patch management that require lots of manual approvals, verifications and rollouts. You'll be glad you did.
Not using Puppet Enterprise yet? Get started with your free trial today.
Learn More
- Read about how Puppet is removing harmful technology from its products
- Learn about the powerful estate reporting capabilities with Continuous Delivery for Puppet Enterprise
- What's the difference between continuous delivery vs. deployment?