Blog
May 22, 2022
How to Express Hiera Data: What It Is, Paths, and Flowcharts

Configuration Management,
How to & Use Cases
The subject that generates the most questions for me from the Puppet community is Hiera. To address some common Hiera data problems, I've identified all the ways that data can be expressed within Puppet, listed the pros and cons of each, and made recommendations as to when each method should be used.
What is Hiera in Puppet?
Back to topHiera is a key-value configuration data lookup system built into Puppet. It's used for separating data from Puppet code. It's pronounced HIGH-ruh.
Expressing Hiera Data in Puppet
I get so many questions about Hiera because it's a tool for storing and accessing site-specific data, and people doing automated configuration management often try to access data within reusable code. Many people think the ONLY place data can live is within Hiera, but that's not always the case (more on that later).
Here's a simplified flow chart that details the choices you need to make expressing your configuration data.
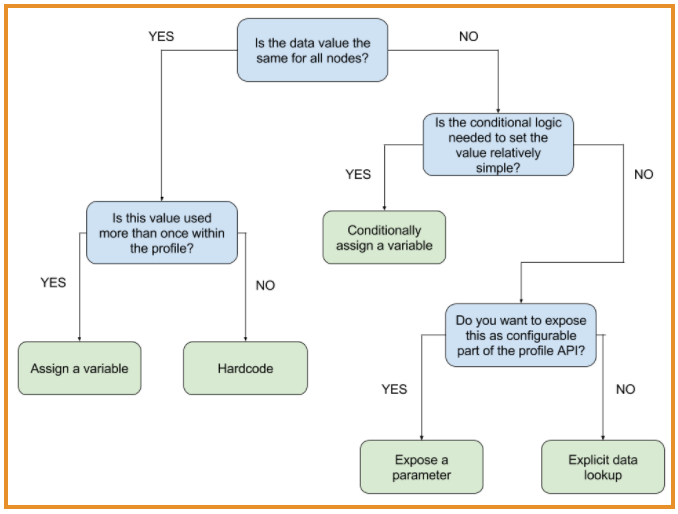
What is Data and What is Code?
This issue of what constitutes data is the first wrinkle in devising what I call a data escalation path. For background reading, the docs page on Puppet roles and profiles does a great job of describing the difference between a component module and a profile.
To quickly summarize: A component module is a general-purpose module designed to model the configuration of a piece of technology (e.g., Apache, Tomcat or ntpd), and a profile is an organization-specific Puppet module that describes an organization's implementation of a piece of technology. (We also use the term "site-specific" to refer to an organization's own particular data.)
For example, an Apache profile that an organization creates for itself might use the official Puppet Apache module to install and configure Apache. But the profile might also contain resources for an organization's SSL certificates or credentials, layered on top of the configuration provided by the Puppet Apache module. The resource(s) modeling the SSL certificate(s) are necessary only for that particular organization, which is why they don't show up in the official Puppet Apache module.
⚙️ See the pieces come together with a demo from the Puppet team >>
In this example, the official Puppet Apache module itself represents the code, or the generic and reusable aspect of the configuration (as any good component module would). The profile contains the organizational (or site-specific) data that is fed to the component module (or code) when that module is used. This separation — and the fact that data can be represented within the same constructs used to represent code — is frequently a source of confusion or frustration for new Puppet users (and especially for users with a background in object-oriented programming, which is almost antithetical to Puppet's declarative coding approach).
Data within a profile can come in different forms:
- A variable assigned within the profile.
- A Hiera/data lookup (done explicitly, or by way of the automatic parameter lookup).
- A parameter's value when the profile is declared.
With the above items all considered to be data, which option do you choose? It's this question that the data escalation path will answer.
NOTE: This post specifically covers data escalation paths within profiles, and NOT within component modules. Unless explicitly noted, assume that recommendations apply ONLY to profiles, and not component modules (since profiles represent site-specific data).
Why an Escalation Path?
The decisions you make when writing Puppet manifests will seldom be plain and obvious. Instead of focusing on whether something is in the right place, it's better to think about the ways that complexity can help you solve problems.
You can absolutely put everything you would consider data inside Hiera, and that would immediately provide you with a way to handle most use cases. But the legibility of your Puppet manifest suffers when you have to jump back to Hiera every time you need to retrieve or debug a data value (which is a very labor-intensive thing to do if you don't have direct access to the Puppet servers). Plus, things like resource dependencies are particularly hard to model in Hiera data, as opposed to using resource declarations within a class.
For simpler use cases, putting data into Hiera isn't necessary. But once you reach a certain level of code complexity, Hiera becomes extremely useful. I'm going to define those "certain levels of complexity" explicitly here, as well as both the pros and the cons for each method of expressing data within your profiles.
Back to topHardcoding Variables
The term "hardcoding" is wrapped in quotes here because traditionally the term has negative connotations. When I refer to hardcoding, I'm talking about directly editing an item within a Puppet manifest, without assigning a variable. In the example below, if you opened up the Puppet manifest and changed the owner from 'root' to 'puppet', that would be considered hardcoding the value:
file { '/etc/puppetlabs/puppet/puppet.conf':
ensure => file,
owner => 'root',
group => 'root',
mode => '0644',
source => 'puppet:///modules/mymodule/puppet.conf',
}Hardcoding has a negative connotation because typically, when someone would hardcode a value in a script, it represented a workaround where a data item is injected into the code — and mixing data and code means that your code is no longer as generic and extensible as it once was.
That concern is still valid for Puppet: If you open up the official Puppet Apache module and change or add a site-specific value within that component module, then you ARE, in fact, mixing data with code.
If instead you edit the Apache profile for your organization and change a value in that profile, then you're changing site-specific data in something that is already considered site-specific. The difference is that the official Puppet Apache module is designed to be extensible, and used where necessary, while the profile is meant to be used only by your own organization (or site, or group).
Hardcoding a value is the easiest method to understand: Something that was previously set to one value is now set to another value. It's also the easiest change to implement — you simply change the value and move along.
If done correctly, someone could change the value without needing to understand the Puppet DSL (domain specific language — i.e. the rules governing Puppet code in a Puppet manifest). Finally, because it's simply text, a hardcoded value cannot be overridden, and the value is exactly the same for all nodes.
Pros
- The easiest technique to understand: Something was changed from one value to another.
- The easiest change to implement.
Cons
- If you hardcode the same value in multiple places, then changing that value requires multiple individual changes.
Recommendations
You should hardcode a value when:
- The value applies to EVERY NODE being managed by Puppet.
- The value occurs once. If it occurs more than once within a manifest, use a variable instead.
Assigning a Variable
The next logical step after hardcoding a value is to assign a variable within a Puppet manifest. Assigning a variable is useful when a value is going to be used in more than one place within a manifest. Because variables within the Puppet DSL cannot be reassigned, and because variables within a manifest cannot be assigned or changed by Hiera, variables are considered private to the implementation.
This means they can be changed only by users with permission to change Puppet manifests, not by people who are responsible for using the console to pass data to the code written by manifest authors. So variables really assist writers of Puppet code more than they assist consumers of Puppet code.
Anytime there's a data value that will be expressed more than once within a Puppet manifest, it's recommended that you use a variable. In the future, if that value needs to be changed, all you need to do is change the variable's value, and it will be updated wherever the variable was used. Below is an example of that concept in action:
$confdir = '/etc/puppetlabs/puppet'
file { "${confdir}/puppet.conf":
ensure => file,
owner => 'root',
group => 'root',
mode => '0644',
source => 'puppet:///modules/mymodule/puppet.conf',
}
file { "${confdir}/puppetdb.conf":
ensure => file,
owner => 'root',
group => 'root',
mode => '0644',
source => 'puppet:///modules/mymodule/puppetdb.conf',
}Pros
- Assigning a variable provides a single point within a manifest where data can be assigned or changed.
- Assigning a variable within the DSL makes it visible to anyone reviewing the Puppet manifest. This means you don't need to flip back and forth between Hiera and Puppet to look up data values.
Cons
- The value applies to EVERYONE — it must be changed if a different value is desired, and that change applies to everyone.
- No ability to override a value.
Recommendations
You should assign a variable when:
- The data value shows up more than once within a manifest.
- The data value applies to EVERY node.
Conditionally Assigning a Variable
In the previous section on assigning a variable, I recommend that variables be used only when their value applies to EVERY node. But there is a way to work around this: conditional statements.
Conditional statements in the Puppet DSL (such as if, unless, case, and the selector operator) allow you to assign a variable once, but assign it differently based on a specific condition. Using the previous example of Puppet's configuration directory, let's see how that would be assigned differently, based on the system's kernel fact:
$confdir = $facts['kernel'] ?
'windows' => 'C:\\ProgramData\\PuppetLabs\\puppet\\etc',
default => '/etc/puppetlabs/puppet',
}
file { "${confdir}/puppet.conf":
ensure => file,
owner => 'root',
group => 'root',
mode => '0644',
source => 'puppet:///modules/mymodule/puppet.conf',
}
file { "${confdir}/puppetdb.conf":
ensure => file,
owner => 'root',
group => 'root',
mode => '0644',
source => 'puppet:///modules/mymodule/puppetdb.conf',
}Conditionally assigning a variable has its own section because when people think about the choices they have for expressing data within Puppet, they usually think of Hiera. Hiera is an excellent tool for conditionally assigning a value, based on its internal hierarchy. But what if the conditional logic you need to use doesn't follow Hiera's configured hierarchy? Your choices are to:
Edit Hiera's hierarchy to add the logic you need (which is potentially a disruptive change to Hiera that will affect lookups), or Use conditional logic within the DSL.
Since we're talking about an escalation path, conditionally assigning a variable is the next logical progression when complexity arises.
Pros
- Values can be assigned based on whatever conditional logic is necessary.
- Values are assigned within the Puppet DSL, and thus are more visible to Puppet code reviewers (versus reviewing Hiera data, which may be located elsewhere).
- Reusability remains intact: The variable is assigned once, and used throughout the manifest.
Cons
- Variables still cannot be reassigned or overridden.
- Conditional logic can grow to become stringy and overly complex if left unchecked.
- Conditional logic is syntax-heavy, and requires knowledge of the Puppet DSL (i.e., it's not something easily used by people who don't know Puppet).
Recommendations
You should use conditional logic to assign a value within a profile when:
- The conditional logic isn't overly complex.
- The conditional logic is different from the Hiera hierarchy.
- Visibility of the data value within the Puppet DSL is a priority.
Hiera Data Lookups and Class Parameters
Puppet's data lookup tool is Hiera, and Hiera is an excellent way to model data in a hierarchical manner based on layers of business logic. Demonstrating how Hiera data lookup works is the easy part; implementing it (and knowing when to do Hiera calls) is another story.
Before we get there, it's important to understand that Hiera data lookups can be done ad hoc through the use of the hiera() or lookup() functions, or through the automatic class parameter lookup functionality. The previous links will give you detailed explanations. Briefly, if a class is declared and a value is not explicitly assigned for any of the class's parameters, Hiera will automatically do a lookup for the full parameter name. For example, if the class is called 'apache' and the parameter is called 'port', then Hiera does an automatic parameter lookup for apache::port.
We'll get back to automatic parameter lookups in a second, but for now let's focus on explicit lookups. Here's an example using both the older hiera function and the newer lookup function:
$apache_port = hiera('apache_port')
$apache_docroot = lookup('apache_docroot')Explicit lookups using one of the above functions are easier to see and understand when you're new to Puppet, because the automatic parameter lookup functionality is relatively hidden to you (should you not be aware of its existence). More importantly, explicit lookups within a Puppet class are considered to be private to that class.
By "private," I mean the object-oriented programming definition: The data is limited in scope to this implementation, and there's no other external way to override or affect this value, short of changing what value Hiera ends up returning. You can't, for example, pass in a parameter and have it take precedence over an explicit lookup — the result of the lookup stands alone.
More than anything, the determining factor for whether you use an explicit lookup or expose a class parameter to the profile should be whether the Hiera lookup is merely a shorthand for getting a value that others SHOULDN'T be able to change, or whether this value should be exposed to the profile as part of the API. If you don't want people to be able to override this value outside of Hiera, then an explicit lookup is the correct choice.
Explicit Hiera Data Lookup Pros
- No need for conditional logic since Hiera is configured independently. Simply do a lookup for a value, and assign it to a variable.
- Using a lookup function is a visible indicator that the data lives outside the DSL (in Hiera).
Explicit Hiera Data Lookup Cons
- Loss of visibility: The data is inside Hiera's hierarchy, and determining the value requires invoking Hiera in some manner (as opposed to simply observing a value in the DSL).
- If the lookup you want to perform doesn't conform to Hiera's existing hierarchy, then Hiera's hierarchy will need to be changed, which is disruptive.
Explicit Lookup Recommendations
You should use an explicit data lookup when:
- The data item is private to the implementation of the class (i.e., not exposed as an API to the profile).
- The value from Hiera should not be overridden within the Puppet DSL.
Class Parameters
API vs. Internal Logic
When building a profile, the implementation of the profile (i.e., anything between the open and closing curly braces {} of a class definition: class apache { … } ) is considered to be private. This means that there really are no guarantees around specific resource declarations as long as the technology is configured properly in the end. Class parameters are considered to be part of the profile's API, and thus there's a guarantee that existing parameters won't be removed or have their functionality changed within a major release (if you follow semantic versioning).
More specifically, exposing a parameter indicates to your Puppet code users that this is something that can be set or changed. Think of computer hardware and the differentiation between Phillips head screws and Torx screws. The Phillips head screws usually mean that customer intervention is allowed, much the same way that parameters indicate data values that can be changed, while Torx screws usually mean that customer intervention is disallowed, much the same way as variables or explicit lookups within a profile cannot be reassigned or overridden.
As referenced in the previous section, this document on the automatic class parameter lookup functionality describes the order of precedence for setting class parameters:
- Parameter values are explicitly set with a resource-like class declaration.
- Puppet performs a Hiera lookup in the style of <CLASS NAME>::<PARAMETER NAME>.
- The default value set in the class definition.
By exposing a class parameter to your profile, you allow for the data to be entered into Hiera without needing an explicit lookup in the profile. Additionally, class parameters can be specified during a resource-like class declaration that allows the user to override the Hiera lookup layer and pass in their desired value. The user understands that class parameters are Puppet's way of allowing input and altering the way Puppet configures the piece of technology. In this way, class parameters aren't merely another method for performing a Hiera lookup; they're also an invitation for user input.
Discoverability and Extensibility
One important distinction with class parameters: The Puppet Enterprise console is able to discover class parameters and present them visually. It can do this because Puppet Server has an API that exposes this data, and that means parameters and classes can be queried and enumerated. Explicit Hiera lookups are not discoverable in the same way; you will need to search through your codebase manually.
Next, class parameters can have their values assigned by an external node classifier, or ENC, but explicit Hiera lookups cannot. An ENC is an arbitrary script or application that can tell Puppet which classes a node should have. (For more information, refer to this document on ENCs.) For Puppet Enterprise, the Puppet Enterprise console acts as an ENC.
Finally, consider the extensibility of explicit lookups versus class parameters. Puppet introduced the lookup() function a while back as a replacement for the hiera() function, which means that over time, all hiera() function calls will need to be converted to lookup() function calls. Class parameters have remained largely unchanged since their introduction (with data types being an additional change), so people using class parameters and the automatic parameter lookup don't need to convert all those explicit lookups. In this case, explicit lookups may require more work than class parameters when performing an upgrade.
Because these two lookups have two fundamentally different purposes, I'm treating their usages separately.
Class Parameter Lookup Pros
- Signals to users of Puppet code that this data item is configurable.
- Allows the value to be assigned either by the Puppet Enterprise console (or other configured ENC) or Hiera.
- Classes and parameters are discoverable through the Puppet Server API.
Class Parameter Lookup Cons
- Automatic parameter lookup is unexpected if you don't know it exists.
- Loss of visibility: The data is inside Hiera's hierarchy, and determining the value requires invoking Hiera in some manner (as opposed to simply observing a value in the DSL).
- Each parameter is unique, so even if multiple profiles expose a parameter of the same name that requires the same value, there needs to be a value in Hiera for each unique parameter.
Class Parameter Recommendations
You should expose a class parameter when:
- You require the conditional logic within Hiera's hierarchy to determine the value of a data item.
- If or when you need to override the value using the Puppet Enterprise console (or other configured ENC).
- To indicate that this part of the profile is configurable to users of Puppet code.
Summary of Hiera Data Expression
Writing extensible code and keeping configuration data separate are always in the back of every Puppet user's mind, but the mechanics of how to achieve this goal can seem daunting. With this post, I hope you now have a clearer path for structuring your Puppet code!
Learn More
- Get insights from a Puppet debugger on writing and inspecting code