Recent Puppet Releases
Recent Puppet Releases
Puppet Enterprise Platform
2025.10 Release Notes 2025.9 Release Notes
Explore Puppet Enterprise Advanced
Starting with the next Puppet Enterprise major version (projected August 2026) Puppet Enterprise will transition from the current “Long Term Support” and “Short Term Support” model (STS/LTS) model to the ‘Latest’ and ‘Latest -1’ support model. For full details, see Puppet Enterprise Platform Support Lifecycle.
Back to topPuppet Enterprise (PE) 2025.10 is now available.
This release ensures consistent behavior when working tasks and plans.
What’s new
- Resolved: An issue affecting the ability to list tasks and plans has been addressed.
Learn more
For a complete list of enhancements, fixes, Puppet-wide agent deprecations, and upgrade notices introduced recently, see the PE 2025.9 Release Notes
2025.9 Release Notes 2023.8.9 Release Notes
Explore Puppet Enterprise Advanced
Starting with the next Puppet Enterprise major version (projected August 2026) Puppet Enterprise will transition from the current “Long Term Support” and “Short Term Support” model (STS/LTS) model to the ‘Latest’ and ‘Latest -1’ support model. For full details, see Puppet Enterprise Platform Support Lifecycle.
We are pleased to announce Puppet Enterprise (PE) 2025.9 and 2023.8.9 are now available.
The latest Puppet Enterprise releases focus on strengthening operational reliability, reinforcing security posture, and giving teams better visibility and control as they manage complex infrastructure environments. Together, these releases allow organizations to move forward with confidence, balancing stability, security, and operational efficiency based on their needs.
Back to topPuppet Enterprise 2025.9
Operate with fewer interruptions
Puppet Enterprise 2025.9 reduces friction in common operational areas so teams can maintain predictable automation, recover more quickly when issues occur, and spend less time diagnosing tooling behavior.
This release helps teams:
- Maintain consistent patching and automation outcomes
- Reduce disruption during maintenance windows
- Keep systems available, compliant, and under control
Greater consistency and visibility in Advanced Patching:
Improvements to advanced patching workflows provide clearer feedback when patch group creation fails, add retry support when issues occur, and introduce real time visibility into patching progress.
Teams can now monitor patch execution as it happens, adjust patching strategies as environments change, and maintain momentum during maintenance windows without unnecessary guesswork.
More reliable and manageable automation execution:
Teams can now edit workflows or stop running workflows directly from the Puppet Enterprise console or via equivalent APIs. This gives operators greater control when conditions change and helps reduce the impact of long running or misconfigured automation.
In addition, fixes to Infra Assistant plan execution and browser certificate handling improve consistency across environments.
Strengthened security and platform foundations
Puppet Enterprise 2025.9 reinforces the underlying platform so it remains a trusted part of security and compliance sensitive environments.
Key outcomes include:
Reduced exposure to known vulnerabilities
This release includes security fixes across core components, helping organizations lower risk associated with outdated dependencies.
Support for modern operating systems
Expanded agent support, including Debian 13 on amd64 and aarch64, helps teams stay aligned with current platform standards.
Simpler, more maintainable integrations
The removal of deprecated metrics APIs reduces long term maintenance overhead and encourages use of supported interfaces.
Faster orchestration
Performance improvements were made to the orchestrator, improving responsiveness when selecting tasks and plans in the PE console and when running individual tasks and plans.
Back to topPuppet Enterprise 2023.8.9
Security maintenance with minimal operational change
Puppet Enterprise 2023.8.9 is a maintenance focused release designed for organizations that prioritize stability while remaining on a supported version of Puppet Enterprise.
This release helps teams:
- Address known security vulnerabilities without introducing new operational complexity
- Maintain compatibility with modern operating systems
- Remain aligned with supported versions of Puppet Enterprise
Key outcomes include:
Complete security remediation
This release includes the same set of security fixes as newer PE versions, allowing teams to reduce exposure to known vulnerabilities while maintaining a conservative operational posture.
Continued support for modern agents
Agent support for Debian 13 on amd64 and aarch64 ensures compatibility with current operating systems while remaining on the 2023.8 release line.
Back to topWhy upgrade?
Upgrading to the latest supported Puppet Enterprise releases helps organizations:
- Reduce operational risk through more predictable patching and automation workflows
- Improve visibility and control across maintenance and automation activities
- Strengthen security posture with fixes for known vulnerabilities
- Align infrastructure automation with modern operating systems and environments
- Maintain compliance by staying on supported versions of the platform
Learn more
For a complete list of enhancements, fixes, Puppet-wide agent deprecations, and upgrade notices, see:
2025.8 Release Notes2023.8.8 Release Notes
Explore Puppet Enterprise Advanced
Starting in August 2026, Puppet is transitioning its Puppet Enterprise® software support offerings from the “Long Term Support” and “Short Term Support” model to the "Latest" and "Latest - 1" model. See release notes for important information on how this may impact you.
We are pleased to announce Puppet Enterprise (PE) 2025.8 and 2023.8.8 are now available.
The latest Puppet Enterprise releases strengthen operational reliability and reinforce your security posture, helping teams stay confident and productive as they manage complex infrastructure environments.
Greater consistency in Advanced Patching
PE 2025.8 resolves an issue that could interrupt patching workflows when nodes were removed from all patch groups. With this fix, teams can maintain predictable Puppet runs and avoid unnecessary troubleshooting so they can focus on higher value work.
Strengthened security with a complete CVE fix
Both PE 2025.8 and PE 2023.8.8 include the full resolution for CVE-2025-58767, ensuring your Puppet Server dependencies are up to date and secure. This gives enterprises the assurance that their automation foundation remains protected against known vulnerabilities.
Learn more
See the full technical details in the release notes:
PE 2025.8 Release Notes PE 2023.8.8 Release Notes
2023.8.7 Release Notes2025.7 Release Notes
Explore Puppet Enterprise Advanced
Starting in August 2026, Puppet is transitioning its Puppet Enterprise® software support offerings from the “Long Term Support” and “Short Term Support” model to the "Latest" and "Latest - 1" model. See release notes for important information on how this may impact you. Until the transition, PE and Puppet Enterprise Agent (PEA) entries will continue to be updated regularly.
We are excited to announce Puppet Enterprise (PE) 2025.7 and Puppet 2023.8.7 are now available, delivering meaningful improvements in automation productivity, operational reliability, and security. Together, these releases help teams modernize infrastructure operations while maintaining the stability and predictability required in enterprise environments.
Accelerate automation with AI assisted workflows
New in PE 2025.7
PE 2025.7 introduces new enhancements to Infra Assistant – an exclusive capability of Puppet Enterprise Advanced - designed to help teams build and evolve automation more efficiently. Natural language assisted workflows for Puppet code, tasks, and plans reduce time to value, streamline collaboration, and lower the barrier to scaling automation across teams. Performance and setup improvements further support faster, smoother daily interactions.
Greater control and insight for patching operations
Enhanced in PE 2025.7
Enhancements to Advanced Patching in Puppet Enterprise Advanced give teams clearer visibility and oversight into patching activities, helping reduce operational risk and improve confidence in patch execution. Key improvements include:
- Simpler patch group management, making it easier to adapt patching strategies as environments change
- Clearer visibility into patch schedules and run status, helping teams quickly understand what is patched and what still needs attention
- Proactive alerting for patching activity, enabling faster response to issues that could impact availability or compliance
These updates support more predictable patching outcomes and help teams maintain security and compliance with less manual effort.
Expanded platform support for modern environments
Available in both 2025.7 and 2023.8.7
Both releases extend support for newer operating systems, including Red Hat Enterprise Linux 10. This allows organizations to modernize infrastructure while continuing to rely on Puppet Enterprise for consistent automation and governance across mixed environments.
Stronger Security Posture
Delivered in both 2025.7 and 2023.8.7
Both releases incorporate multiple security updates and defect fixes across Puppet Enterprise, agents, and supporting services. These improvements help reduce exposure to known vulnerabilities, strengthen overall platform stability, and reinforce Puppet Enterprise as a trusted foundation for managing critical infrastructure.
Why Upgrade?
- Move faster with AI assisted automation
- Expand your deployment options with RHEL 10 support
- Reduce operational risk with more resilient backups
- Safeguard your infrastructure with critical security fixes
Learn more
For full technical details and a complete list of enhancements and fixes, see:
2023.8.6 release notes 2025.6 release notes
Explore Puppet Enterprise Advanced
Puppet Enterprise (PE) 2023.8.6 and 2025.6 (PE and PE Advanced) are here!
We are excited to announce that Puppet Enterprise (PE) 2023.8.6 and 2025.6 (PE and PE Advanced) are now available.
PE 2025.6 incorporates support for Puppet Edge, a powerful new capability for Puppet Core and the Puppet Enterprise platform that extends governance to network and edge devices, including firewalls, routers, switches, and POS systems. Valuable enhancements are also made to Advanced Patching, available exclusively in PE Advanced.
Both PE 2025.6 and PE 2023.8.6 receive more than 50 important security and bug fixes and removal of support for several unsupported operating systems.
Back to topNew in 2025.6
Extending Puppet to the Edge
Puppet Edge addresses the risk of unmanaged network devices with agentless, task-based orchestration, complementing existing desired state automation for servers and delivering flexibility without compromising compliance. Teams can now manage their full infrastructure estate more easily without having to maintain and operate multiple tools.
With features like Playbook Runner that retains value from prior automation investments, consistent policy management across distributed systems, embedded visibility into device state, and seamless integration with Puppet workflows, organizations can apply the same trusted automation and governance used for servers to edge environments – achieving broader consistency and control across hybrid estates.
Teams running Puppet Enterprise Advanced gain additional capabilities, including advanced orchestration workflows from the PE console and AI-generation of content to help manage devices using the new Infra Assistant: code assist capability.
Advanced Patching: New PE console capabilities
From the PE console, Advanced Patching users can:
- Edit a maintenance window
- Edit a blackout window
- Edit scheduled patch jobs
Advanced Patching API: New endpoints
New API endpoints are included to:
- Edit an existing maintenance window
- Edit an existing blackout window.
- Edit an existing patch job.
Resolved issues
The Puppet team is committed to resolving issues and this release incorporates fixes for the following issues (refer to release notes for additional details)
PE 2023.8.6 and PE 2025.6
- Puppet backup create/restore no longer fails when the puppet_enterprise::puppetdb_port is changed
- Puppet::Network::Format error message is no longer missing actionable details
PE 2025.6 only
- Infra Assistant no longer fails to start up when replication is enabled
- Advanced Patching no longer fails to startup when replication is enabled
- Tasks and plans that are not intended to be run directly by users are no longer displayed
- Plans fail to submit results if tasks are still running
Deprecations and removals
Agent platforms removed
Support is removed in both 2023.8.6 and 2025.6 for the following operating system platforms:
- macOS 11 x86_64
- macOS 12 x86_64
- macOS 12 ARM
Client tool platforms removed
Support is removed in both 2023.8.6 and 2025.6 for the following client tool platforms:
- macOS 11 x86_64
- macOS 12 x86_64
- macOS 12 ARM
- macOS 12 M1
- macOS 12 M2
PE console button removed
In 2025.6, following the availability of Puppet Edge, the button to create network devices has been removed in the PE console to simplify the user interface.
Back to topSecurity fixes
It is important to leverage supported releases of software to ensure protection against an ever-evolving threat landscape. As listed in the respective release notes, 2023.8.6 and 2025.6 each incorporate fixes for more than 50 CVEs.
August 5th 2025
We are excited to announce that Puppet Enterprise (PE) 2023.8.5 and 2025.5 (PE and PE Advanced) are now available, including new platform support, as well usability enhancements, security improvements, and other important fixes.
Benefits of upgrading to PE 2025.5:
- Rerun plans from the PE Console
- Various bug fixes and security enhancements
Benefits of upgrading to PE 2025.5 and 2023.8.5:
- Filter plans by name in the PE Console
- Improved file sync configuration parameters
- Agent platform support for Red Hat Enterprise Linux (RHEL) 10 x86_64
- Security, reliability and performance enhancements
For full details of what’s included in each release, see the PE docs:
IMPORTANT: Upcoming Changes to the Puppet Enterprise Lifecycle
Beginning in August 2026, Puppet Enterprise will adopt a new “Latest and Latest-1” support model.
This change will accelerate innovation and simplify lifecycle management by:
- Delivering continuous access to valuable new features
- Improving security and compliance through more frequent updates and patches
- Providing a more predictable, simplified support timeline
Under the new model:
- Latest series: Receives full support (new features, fixes, security updates) for 12 months.
- Latest-1 series: Receives defect fixes and only minor changes for an additional 12 months after being superseded.
This replaces the previous Long-Term Support (LTS) model, which offered up to two years of support with limited feature delivery.
How does this impact current release streams?
- PE 2023.8.z series (LTS) will be the final series supported under the LTS support model. Maintenance releases will continue until August 2026, when the series reaches end of life (EOL). This timing coincides with the launch of the new lifecycle model. Customers should begin planning upgrades to ensure uninterrupted support.
- PE 2025.y series (Current latest): This series will continue receiving the latest updates until August 2026, when the next major PE version is released. At that point, 2025.y will transition to Latest-1 and receive defect fixes and only minor updates until EOL in August 2027.
Further guidance will be provided ahead of the transition in August 2026 but we recommend that planning start now to ensure a smooth transition and to gain from the latest capabilities and associated business outcomes.
Release Notes Learn More About Puppet Enterprise Advanced
June 2025
Time spent finding the right information, knowing which services to use, and reliance on Puppet experts slows velocity and creates a productivity bottleneck for infrastructure teams. Infra Assistant, new in PE 2025.4 and exclusive to Puppet Enterprise (PE) Advanced, transforms how teams interact with Puppet by enabling you to talk to your Puppet infrastructure using natural language.
This release also features updates to Advanced Patching as well as usability enhancements, fixes, and expanded platform support.
Back to topNew in this release
Introducing Puppet Infra Assistant (exclusive to PE Advanced)
Infra Assistant, available within the Puppet Enterprise console, safely unlocks infrastructure data and services for everyone — not just Puppet power users. Authorized users can now safely access real-time infrastructure data more easily to make faster, data-driven decisions with confidence.
Customers with PE Advanced licenses are entitled to activate Infra Assistant today. For information about enabling the Infra Assistant, see the docs here. To upgrade to the PE Advanced license, contact our sales team.
Infra Assistant is the first of several exciting AI-powered capabilities we have planned, including agentic code generation and anomaly detection.
Back to topImprovements in this release
Enhancements to Advanced Patching (exclusive to PE Advanced)
In addition to general usability improvements within the Advanced Patching feature, this release introduces support for creating patch groups in the console with fact-based rules for dynamic membership.
Previously, the PE console supported creating patch groups with pinned nodes, while dynamic membership (using fact-based rules) was available only via API.
You can now create patch groups in the console with pinned membership, or using fact-based rules for dynamic membership, or both. At patch job runtime, nodes that match your defined rules, and that aren’t already pinned to another patch group, are included automatically. This update simplifies patching workflows and reduces manual effort.
Back to topUpdates in this release
Updated agent support (PE and PE Advanced)
This release adds agent support for the following operating systems:
- macOS 15 x86_64
- Solaris10 SPARC
- SUSE Linux Enterprise Server (SLES) 15 ppc64
2023.8.3 release notes 2025.3 release notes
Learn More About Puppet Enterprise Advanced
We are excited to announce that Puppet Enterprise (PE) 2023.8.3 and 2025.3 (PE and PE Advanced) are now available.
We’ve expanded primary and agent platform support, as well as incorporated improvements in the popular Advanced Patching with Vulnerability Remediation capabilities introduced exclusively in Puppet Enterprise Advanced. Patching infrastructure in a timely manner remains one of the most important defensive tactics that platform teams can leverage to prevent unplanned outages and compromise. Advanced Patching distributes patches across the infrastructure estate quickly and efficiently at scale.
Benefits of upgrading to PE Advanced 2025.3:
- A variety of usability improvements and bug fixes have been made to Advanced Patching and Vulnerability Remediation
Benefits of upgrading to PE 2025.3 and 2023.8.3:
- Primary platform support for Amazon Linux 2023 has been added
- Agent platform support for Amazon Linux 2023 (FIPS) and Microsoft Windows Server 2025 has been added
- Security and performance enhancements
Release Notes Learn more About Puppet Enterprise Advanced
March 2025
Unresolved vulnerabilities can lead to costly consequences, especially for enterprise organizations where continuous compliance is critical. Vulnerability Remediation, new in PE 2025.2.0 and exclusive to Puppet Enterprise (PE) Advanced, reduces the mean time to remediate vulnerabilities, empowering cross-team collaborative workflows for security and IT operations, ensuring your systems remain secure and compliant.
Also included in this release are improvements to the recently introduced Advanced Patching feature and new agent support for the wider Puppet Enterprise platform.
Back to topNew in this release
Introducing Vulnerability Remediation (exclusive to PE Advanced)
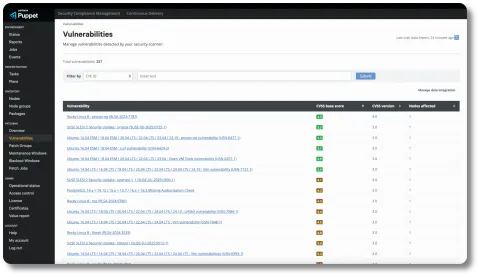
With an ever-increasing volume of common vulnerability and exposures being reported, it is critical to ensure that patches are applied quickly and efficiently. The addition of Vulnerability Remediation within the Advanced Patching feature in the PE console streamlines vulnerability management for enterprise security, enabling:
- Powerful integration: Ingest data from popular security scanners to review vulnerability information, sort by criticality, and apply remediation quickly and easily right from within Puppet. Nessus is integrated out-of-the-box with other scanners supported via an extensible architecture and open API framework.
- Greater collaboration: Reduce mean time to remediate (MTTR) with more efficient information exchange between platform and security teams. (No more clumsy spreadsheets and endless fire drills!)
- Improved resilience: Apply or roll back patches, reconfigure applications, or upgrade to new versions based on CVSS criticality scores for each vulnerability.
Improvements in this release
Enhancements to Advanced Patching (exclusive to PE Advanced)
This release also includes updates to the Advanced Patching feature in PE Advanced, including:
- Comprehensive patch management: Redefine patch groups, configure scheduled patch jobs, and view vulnerability data at the node level.
- Improved scheduling control: Manage existing maintenance schedules and get warnings about potential scheduling overlaps when configuring patch jobs.
- Dynamic patch grouping: Group nodes automatically based on specific criteria defined by your infrastructure needs and patch management process.
- Improved usability: General improvements address bugs and usability issues from previous releases.
Updates in this release
Updated agent support (PE and PE Advanced)
- This release adds agent support for the following operating systems:
- macOS 15 ARM
- Fedora 41 x86_64
- Microsoft Windows Server 2016 FIPS
With the addition of another exclusive, value-added capability, Puppet Enterprise Advanced remains the best way to get the most out of your infrastructure with Puppet. Advanced Patching delivers more value for Puppet Enterprise Advanced users, giving them access to a brand-new approach to patching.
LEARN MORE ABOUT PUPPET ENTERPRISE ADVANCED
Back to topAdvanced Patching
The Advanced Patching module, available exclusively to Puppet Enterprise Advanced customers, lets Puppet admins continuously manage their patching workflows more easily. Features in this initial release include:
- A graphical user interface (GUI) for ease of use
- Dedicated patching groups for nodes
- Support for maintenance and blackout windows
- Fine grained Role-Based Access Control (RBAC)
These features are included alongside the familiar Puppet workflows that you already love.
The initial release of Advanced Patching will receive numerous enhancements throughout 2025.
Advanced Patching is available immediately to Puppet Enterprise Advanced users. At this point, these capabilities cannot be bought individually or applied to other Puppet entitlements and are only available to Puppet Enterprise Advanced customers.
PUPPET ENTERPRISE ADVANCED DEMO
September 19, 2024
With the addition of two exclusive, value-adding capabilities, Puppet Enterprise Advanced remains the best way to get the most out of your infrastructure with Puppet. This simultaneous release of the Observability Data Connector and the enhanced ServiceNow Spoke delivers more value for Puppet Enterprise Advanced users, giving them access to improved monitoring and resource optimization, faster issue resolution, predefined and custom self-service automation workflows, and more.
Back to topFor more information on adding these capabilities to your Puppet Enterprise entitlement, visit the Puppet Enterprise Advanced product page or compare plans on the Puppet Pricing & Plans page.
Observability Data Connector
The Observability Data Connector module, available exclusively to Puppet Enterprise Advanced customers, lets Puppet admins skip the wait and see specific events as they happen. Import key Puppet data into your preferred observability platforms — like Splunk, Data Dog, New Relic, Prometheus, and Grafana — instead of adding yet another tool to their tech stack. Importable data includes:
- Puppet event totals: Shows how many of each event type happened during a report from changed resources to failed resources. Users can use this data to look for issues, identify anomalies, and confirm change consistency between states, environments, and resources.
- Puppet catalog times: Shows the timing of each stage of a Puppet catalog application. This function allows you to see which stages of your catalog are taking the most time so you can identify coding issues early and better manage infrastructure capacity.
Self-Service Automation via the ServiceNow Spoke
The Puppet Spoke for ServiceNow gives platform teams the power to automate without leaving ServiceNow, one of the most popular IT service management platforms (ITSMs) on the market. Select from a number of templated items or create custom automation workflows for your whole team and execute Puppet Tasks and Plans with a click.
This exclusive feature empowers platform teams using Puppet Enterprise Advanced to manage IT infrastructure changes efficiently, troubleshoot problems quickly, and resolve more incidents faster. With the Puppet ServiceNow Spoke, teams have access to:
- Pre-built ServiceNow catalog items: This integration provides a set of pre-defined workflows in the ServiceNow catalog. These template items include routine Puppet tasks like installing the Puppet agent on a node, rebooting a machine, running a package install, managing a service, and more.
- Custom ServiceNow catalog items: With the Puppet Spoke, your teams can also make custom Puppet workflows accessible to non-experts for easy, self-service consumption without needing to log into the Puppet Enterprise console.
The Data Connector and the ServiceNow Spoke are available immediately to Puppet Enterprise Advanced users. At this point, these capabilities cannot be bought individually or applied to other Puppet entitlements, and are only available to Puppet Enterprise Advanced customers.
2023.8.0 LTS RELEASE NOTES 2021.7.9 LTS RELEASE NOTES
DEMO PUPPET ENTERPRISE
August 2024
Back to topPuppet Enterprise 2023.8.0 LTS
The first LTS release built on Puppet 8, 2023.8.0 LTS is designed to support your long-term success with Puppet, featuring improvements to performance, scalability, and security to help your teams automate and manage infrastructure more efficiently.
Whether upgrading from 2021.x LTS or implementing Puppet Enterprise for the first time, Puppet Enterprise 2023 LTS is your gateway to a more robust and secure infrastructure.
Puppet Enterprise 2023.8.0 LTS is the inaugural release of the 2023.x LTS track, which will replace the 2021.x LTS release track after 2021.7.9.
Back to topPuppet Enterprise 2021.7.9 LTS
Alongside the release of our 2023.8.0 LTS, we are also releasing the final version of the 2021.x LTS release track with Puppet Enterprise 2021.7.9. While this version will get security updates and remain supported for the next 6 months, this will be the last major update for this version. In future releases of Puppet Enterprise LTS, the 2021.x LTS release track will be replaced by the 2023.x LTS release track.
In order to continue using the latest version of Puppet Enterprise LTS beyond 2021.7.9, you will need to upgrade to the 2023.x release track.
For information about upgrading to Puppet Enterprise 2023 LTS, see the Puppet documentation on upgrading Puppet Enterprise.
Back to topNew in Puppet Enterprise 2023.8.0 LTS:
- Puppet 8: This release is built on top of Puppet 8, and enhances automation capabilities, offering improved efficiency and security in managing your infrastructure. A complete list of features and improvements contained in Puppet 8 can be found here.
- Improved performance and scalability: Various improvements have been made to our components and services to help improve operational performance and scalability. These include improvements to lockless deploys for Code Manager, PuppetDB, and Orchestrator.
- Improved DR capabilities: We understand the critical nature of maintaining business continuity and have improved the resiliency of promotion and provision actions to help support better disaster recovery processes.
- Updated agent support: This release also adds agent support for the following operating systems:
- Ubuntu 24.04 (amd64 and aarch64)
- RedHat Enterprise Linux 9 ppc64le
- Alma Linux 9 (x86_64 and aarch64)
- Rock Linux 9 (x86_64 and aarch64)
- Amazon Linux 2 (aarch64)
- Fedora 40 (x86_64)
Issues resolved in Puppet Enterprise 2023.8.0 LTS:
This release also contains a variety of bug fixes alongside dependency and security updates. A complete list of changes can be found in the 2023.8.0 release notes here.
EOL for Several Primary Server Platforms
In Puppet Enterprise 2023.8.0 LTS, we've removed support for the following End of Life (EOL) operating systems as infrastructure servers (Primary, Replica, Compiler, or Database) platforms:
- CentOS version 7
- Oracle Linux version 7
- Red Hat Enterprise Linux version 7
- Red Hat Enterprise Linux (FIPS 140-2 compliant) version 7
- Scientific Linux version 7
- Ubuntu 18.04
- SuSE Linux Enterprise Server (SLES) 12
New in Puppet Enterprise 2021.7.9 LTS:
- Legacy facts disabled by default: This ensures that your code base is compatible with Puppet 8 and that there are no issues or blockers with your upgrade path.
- Disabling slow and I/O intensive operation codedirs chown in compiler catalogs.
- Faster Events screen load in the Puppet Enterprise console shows events in the last 30 minutes.
- Updated agent support: This release also adds agent support for the following operating systems:
- Ubuntu 24.04 (amd64 and aarch64)
- RedHat Enterprise Linux 9 ppc64le
- Alma Linux 9 (x86_64 and aarch64)
- Rock Linux 9 (x86_64 and aarch64)
- Amazon Linux 2 (aarch64)
- Fedora 40 (x86_64)
May 21, 2024
In today’s operating reality, organizations need more value from the tools they’re already using. This release adds more features and functionality to Puppet Enterprise to help users do more with their infrastructure, faster and more securely.

With the release of Puppet Enterprise 2023.7, the inclusion of Continuous Delivery lets customers build, test, and deploy Puppet code. Security Compliance Management provides compliance scanning, assessment, and monitoring capabilities within Puppet, using Puppet infrastructure as code to measure security and compliance posture against custom policies and the integrated CIS-CAT® Pro Assessor for maximum compliance visibility.
Additionally, Puppet Enterprise 2023.7 adds previews of premium features to the Puppet Enterprise Console. Get a sneak peek at Impact Analysis (which lets you preview the impact of your next code change on existing configurations before you merge) and Security Compliance Enforcement (policy as code for correcting drift and enforcing desired state configurations hardened against CIS Benchmarks and DISA STIGs) and learn more with new links in the Puppet Enterprise Console.
Puppet Enterprise 2023.7 also includes additional agent support, bug fixes, and security updates to ensure smoother operations, consistent infrastructure uptime, and maximum usability of Puppet Enterprise.
Back to topNew in this release:
- Security Compliance Management is now included with Puppet Enterprise, adding compliance monitoring and assessment insights as part of the same Puppet Enterprise license.
- Continuous Delivery is now included with Puppet Enterprise, adding CI/CD capabilities that let you build, test, promote, and deploy Puppet code and integrate with your current pipelines as part of the same Puppet Enterprise license.
- Security Compliance Management and Continuous Delivery can be accessed from Puppet Enterprise. Users can launch the new consoles by clicking quick links in the Puppet Enterprise console.
- Added agent support for the following operating systems:
- Amazon Linux 2023 amd64
- Amazon Linux 2023 aarch64
- Debian 11 aarch64
- Debian 12 amd64
- Debian 12 aarch64
- macOS 14 ARM
- macOS 14 x86_64
- FIPS 140-2 compliant Red Hat Enterprise Linux (RHEL) 9 x86_64
Issues resolved in this release:
- Fixed an issue where promoting a replica using the disaster recovery workflow could lead to file sync corruption and code deployment failures.
- Fixed an issue where the
recover_configurationcron job could sometimes cause a Puppet server restart. - Included REXML Ruby gem, correcting issues for modules reliant on XML interactions with the REXML library.
- Fixed an issue where pinning a node resulted in the pinned node being incorrectly displayed in the main rules section when a node group was set to match any rule.
- Added use of the full Puppet binary path for backup and restore commands, eliminating certain failures during backup commands (e.g., running the backup command from a cron job).
Security fixes in this release:
- Addressed the following CVEs:
- CVE-2024-22871
- CVE-2024-1597
- CVE-2024-25710
- CVE-2024-26308
- CVE-2023-42503
- CVE-2024-46218
STS RELEASE NOTES LTS RELEASE NOTES DEMO PUPPET
Feb. 6, 2024
You rely on your infrastructure to drive performance, security, and time to value. Puppet Enterprise 2023.6 (STS) and 2021.7.7 (LTS) focus on performance to deliver faster, more efficient automation workflows with a host of updates and enhancements.
Puppet users can expect enhanced increased responsiveness that enables them to meet the demands of modern IT operations faster than before. These releases also improve scalability to ensure that automation remains robust and reliable, even in large IT environments increasing the number of concurrent plans that can run.
Updates in these releases:
PE 2023.6 (STS)
- Identify operational issues affecting infrastructure nodes: The PE console now includes an Operational status page showing the result of the latest checks performed by the
pe_status_checkmodule. Issues requiring your attention are listed under the affected infrastructure nodes. - Run 100+ plans concurrently: PE 2023.6 introduces the
pe-plan-runnerservice, which runs on the primary server by default, allowing concurrent execution of up to 100 plans.pe-plan-runneralso has the potential for further scaling based on available memory on the primary server. - Include or exclude catalog resource edges in catalogs sent to PuppetDB.
- A new guided workflow for configuring and running task jobs.
- Specify ciphers to use when establishing connections to configured LDAP servers.
- Added agent support for AIX 7.3.
PE 2021.7.7 (LTS)
- Added agent support for AIX 7.3.
Issues resolved in these releases:
PE 2023.6 (STS)
- Fixed issues where restoring PE from a backup could fail when
puppetagent was running, if lockless code deployments were enabled, or when setting theclassifier_hostparameter. - Fixed an issue where upgrading the agent to Puppet 8 on FIPS-compliant RHEL 7 or 8 could cause the puppet service to stop unexpectedly.
PE 2021.7.7 (LTS)
- Fixed issues where restoring PE from a backup could fail when puppet agent was running, if lockless code deployments were enabled, or when setting the
classifier_hostparameter.
Security fixes in these releases:
PE 2023.6 (STS) & PE 2021.7.7 (LTS)
- Critical updates to Java, Postgres, and logback.
- Addressing CVE-2023-6378, CVE-2023-6378, CVE-2023-40167, CVE-2023-36479, CVE-2023-41900, CVE-2023-5869, CVE-2024-20952, CVE-2024-20918, CVE-2023-44487, CVE-2023-5072, CVE-2024-20932
STS RELEASE NOTES LTS RELEASE NOTES DEMO PE 2023.4
STS: Oct. 3, 2023
LTS: Sept. 2023
Your increasingly complex IT environment needs to move faster than ever, so we’ve updated Puppet to ensure your IT operations teams can keep pace to drive better performance and scale your enterprise infrastructure. The 2023.4 release of our leading-edge PE release stream (also referred to as STS) includes powerful new improvements that will help you increase operational efficiency by maximizing resources and streamlining processes.
New in these releases:
PE 2023.4 (STS)
- Puppet 8: PE 2023.4 includes Puppet 8, the eighth full release of Puppet’s open source code. Puppet 8 includes updates to configuration reporting, protections for user inputs, and more. Additionally, access to the latest OS versions like OpenSSL 3 and Ruby 3.2 will improve performance and add additional security.
- Effortless certificates management: Auto-renewal alleviates the challenge of manually reinstating expired certificates across your IT.
- Orchestrator enhancements: Improvements to the Orchestrator constrain task concurrency to individual jobs rather than sharing across jobs, allowing independent jobs to start execution without latency.
- PuppetDB efficiency improvements: PuppetDB will make sure reports run smarter with optimized indexes, increasing speed and efficiency.
- New OS support for primary and secondary: MacOS 13 (ARM and x86_64) Agents, Ubuntu 22.04 & RHEL 9 Primary
- Enhanced UI: Edit scheduled plans effortlessly with a simplified interface.
- More enhancements: This release includes several changes designed to increase efficiency and usability.
PE 2021.7.5 (LTS)
- Classifier service flags unmappable legacy facts in node group rules: PE 2021.7.5 generates warning messages to flag uses of certain legacy facts that don’t map to equivalent structured facts in Puppet 8.
- New OS support for primary and secondary: MacOS 13 (ARM and x86_64) Agents, Ubuntu 22.04 and RHEL 9 Primary
- Customizable HTTP-client limits in Orchestrator: Specify connection limit parameters to match infrastructure requirements.
- Configurable socket timeout in Orchestrator: Specify the maximum time before socket timeout by changing the default value.
- Improved error logging for the puppet backup command: In PE 2021.7.5, descriptive error messages will display in the terminal and log file, instead of generic messages displayed in previous releases.
- Added primary server platforms: RHEL 9 x86_64, Ubuntu 22.04 amd64
- Added agent platforms: macOS 13 ARM and x86_64
- Added client tools platforms: macOS 13 ARM and x86_64
- Added patch management platforms: RHEL 9 x86_64
- Removed agent platforms: CentOS 7 aarch64, macOS 10.15, Oracle Linux 7 aarch64, Red Hat 7 aarch64, Scientific Linux 7 aarch64
- Removed client tool platform: macOS 10.15
Issues resolved in these releases:
PE 2023.4 (STS)
- Fixed an issue in which installing a Windows agent through the console could fail when the Test Connections checkbox was selected.
PE 2021.7.5 (LTS)
- Fixed an issue in which installing a Windows agent through the console could fail when the Test Connections checkbox was selected.
Security fixes in these releases:
PE 2023.4
- Addressed CVE-2023-5255.
PE 2023.1 RELEASE NOTES PE 2021.7.3 RELEASE NOTES
These patch releases include fixes and performance upgrades for existing features.
These releases represent the latest updates in the Puppet Enterprise (PE) 2023 and 2021 streams, following the releases of PE 2023.0 and PE 2021.7.2 LTS in January 2023. These new, backward-compatible releases contain fixes and performance upgrades for existing features and functionality.
For a detailed list of enhancements and fixes in PE 2023.1, see the PE 2023.1 release notes.
For a detailed list of enhancements and fixes in PE 2021.7.3, see the PE 2021.7.3 release notes.
For security and vulnerability announcements, see CVE Content.
Performance enhancements in these releases:
- Improved performance when querying PuppetDB
- Improved performance for several functions in the Puppet language
- More reliable warnings when updating Puppet Server
Deprecation of Pure JavaScript Open Notation (PSON) for serializing data in Puppet 7
Resolved issues in these releases:
- Tasks page is available following a software update
- Enabling the lockless code deploy feature no longer causes performance issues in PuppetDB catalog compilation
- Performance issue with Puppet agent runtimes is resolved
- Certificates and keys can be backed up and restored by specifying the certs scope
- Updates implemented to help users enter valid URLs
- Timeouts can be specified for SAML authentication
- User-defined temporary directory is honored during PE restore operations
- Issue that caused an unexpected increase in CPU usage is resolved
Additional issues resolved in PE 2023.1, related to new features in 2023.0:
- Scheduled task jobs run successfully without a defined timeout
- Timeout and concurrency values for scheduled tasks can be viewed and edited in the console
- When tasks are rerun in the console, timeout and concurrency attributes are preserved
- Access rights for remote users can be revoked and reinstated from the console
Security fixes in both releases:
- CVE-2023-1894
- CVE-2023-26048
RELEASE NOTES UPGRADE START PE TRIAL
April 2023
Puppet powers better infrastructure in thousands of organizations worldwide – and changes to Puppet source code always target better efficiency, scalability, and usability. Puppet 8 is the biggest update to Puppet since Puppet 7’s first release in November 2020. Along with a host of behind-the-scenes updates, Puppet 8 adds brand-new features that ensure better security, reliability, and performance, like automatic certificate renewal and an error-proof Strict Mode.
Puppet 8 is included in all Puppet Enterprise releases since PE 2023.4 (STS) and PE 2021.7.5 (LTS).
New in this release:
- Updates to certificate management: Automatic certificate renewal addresses a huge IT ops pain point. With customizable automatic certificate management, Puppet 8 reduces the toil of managing certificates across large fleets, enabling faster security fixes and continuous compliance across your infrastructure.
- Ruby 3.2 and OpenSSL 3: With Puppet 8, Puppet is now on the latest branch of Ruby 3.2 and OpenSSL 3, reducing vulnerability scanning concerns.
- Strict Mode: Puppet 8 introduces Strict Mode, which throws an error rather than allowing incorrectly passed changes (like typos). Strict Mode helps avoid both costly mistakes and unauthorized attempts to reassign variables.
- Default exclusion of unchanged resources from reporting: Unchanged resources will no longer appear in reporting by default, reducing the amount of digging needed to get to actionable insights from each Puppet run.
- Dropping Hiera 3: Removing Hiera 3 trims down the Puppet 8 install for better efficiency and performance.
- If you rely on a Hiera 3 backend, you must convert your backend to Hiera 5.
- Default lazy evaluation of deferred functions: Operate with greater mobility and security when accessing something you don’t want passed through the Puppet infrastructure nodes (e.g., vault secrets).
Puppet 2023.0 is the latest release following 2021.7, now using updated versioning. It’s a backward-compatible release that contains enhancements and resolved issues from our previous major release.
Here are the highlights of Puppet Enterprise 2023.0:
- NIST compliance: Puppet 2023.0 ensures that sensitive information is cleared when a session times out. You can customize the timeout to specify a default value and issue a confirmation message. In this way, you reduce compliance risk for InfoSecOps and administrators. This feature is designed for compliance with National Institute of Standards and Technology (NIST) guidelines.
- Authenticate users in multiple Lightweight Directory Access Protocol (LDAP) domains: Use a prioritized list of LDAP servers to get credentials. In this way, you reduce compliance risk and increase operational efficiency for administrators.
- Streamlined user interface for tasks and plans: Increase observability, throughput, fault tolerance, and operational efficiency with new job and task queue status, task concurrency fine-tuning, default job timeouts, and the capability to stop stalled jobs. View and edit task parameters, targets, and other details. The new functionality is designed to benefit users, operators, and managers.
- Scalability performance improvements to deploy and manage more nodes: Increase operational efficiency and accelerate time to value with new orchestrator task concurrency defaults and improvements. Reporting, database performance, and agent certificate regeneration improvements are provided as well to benefit all users.
Component Updates
- Java 17
Deprecations
Removed primary server platforms:
- CentOS 8
Removed agent platforms:
- CentOS 8
- Debian 9
- Fedora 32
- Fedora 34
- Ubuntu 16.04
Removed patch management platforms:
- Debian 9
- Fedora 34
Puppet Core
Release Notes Explore Puppet Core
Puppet Core enables teams to define, enforce, and maintain consistent system configurations across complex environments. It helps ensure that infrastructure behaves as expected, even as systems scale and evolve.
Puppet Core 8.19 focuses on improving the security and stability of that foundation. This release reduces exposure to known vulnerabilities, simplifies the underlying software footprint, and introduces safeguards that help prevent common sources of failure. The result is a more predictable and resilient operating environment.
Back to topWhy Upgrade
Reduce risk, improve operational consistency, and simplify ongoing infrastructure management across your environments.
- Reduce exposure to known vulnerabilities
This release addresses multiple vulnerabilities across key runtime components, helping reduce security risk without requiring teams to track and remediate dependencies independently. - Improve operational reliability
By strengthening core components and reducing failure conditions, Puppet Core 8.19 helps teams minimize unexpected outages and maintain consistent system behavior across environments. - Simplify maintenance and long-term operations
Improvements to dependency management reduce complexity in the software stack, making environments easier to maintain and less prone to drift or misconfiguration over time. - Strengthen audit readiness and compliance posture
Consistent updates to managed components and alignment with supported runtime environments support continuous compliance efforts and reduce the risk of audit gaps.
What’s New
Introducing targeted improvements that strengthen platform stability, reduce complexity, and enhance the reliability of day-to-day operations.
- Simplified dependency model
Updates to the underlying software stack reduce the number of external components required at install time. This supports cleaner deployments and lowers operational overhead over time. - Coordinated component updates
Core dependencies have been updated to address recently disclosed vulnerabilities. These updates strengthen the runtime environment while maintaining compatibility with existing configurations and workflows. - Improved platform stability safeguards
Additional validation checks help ensure that Puppet Core is deployed with supported runtime components, reducing the likelihood of instability caused by incompatible environments. - Enhanced reliability in day-to-day operations
By addressing common sources of failure and tightening dependency alignment, the platform delivers more consistent behavior across managed systems, especially in large or heterogeneous environments.
Security and Maintenance
This release includes updates that address a broad set of known vulnerabilities across its runtime dependencies. Keeping these components current is a key part of maintaining a secure and stable infrastructure environment.
In addition to vulnerability remediation, this release reduces dependency complexity and adds safeguards that improve long-term maintainability and reduce operational risk.
Back to topLearn More
For detailed technical information, including information about CVEs that have been addressed, review the Puppet Core 8.19 release notes.
Release Notes Explore Puppet Core
Puppet Core 8.18 reinforces the role of Puppet as a stable, vendor-backed foundation for infrastructure automation. This release combines expanded platform coverage with continued security hardening, helping teams reduce operational risk while keeping pace with modern operating systems.
As with all Puppet Core releases, these updates are delivered as tested, hardened builds, removing the need for teams to manage, validate, or certify dependencies on their own.
Back to topA Trusted Automation Foundation, Kept Current
Organizations rely on Puppet Core to provide consistent, reliable automation in environments where security, compliance, and uptime matter. Puppet Core 8.18 continues this approach by strengthening the underlying platform without introducing disruption or forcing changes to established workflows.
This release reflects Puppet’s ongoing commitment to maintaining a clean, supported automation foundation that evolves alongside customer infrastructure.
Expanded macOS Coverage
Puppet Core 8.18 extends support for macOS 15 across both x86_64 and ARM architectures. This allows teams to continue managing macOS systems using the same controls and policies they rely on today.
By delivering macOS agent support in Puppet Core, teams can adopt new operating system versions without the overhead of custom packaging or independent validation.
Security Hardening Embedded in the Platform
This release includes updates to foundational components that help maintain alignment with current security expectations. Rather than requiring customers to track upstream changes or assess individual fixes, Puppet Core bundles these improvements as part of a ongoing release lifecycle.
The result is a platform that continuously strengthens security posture while preserving predictable behavior and operational stability.
Why Upgrade?
Upgrading to Puppet Core 8.18 helps organizations:
- Maintain automation coverage as operating systems evolve.
- Reduce security exposure through CVE remediation and tested updates.
- Rely on a hardened, vendor-backed foundation instead of self-maintained builds.
- Support audit, compliance, and governance objectives with less operational overhead.
Puppet Core 8.18 helps ensure your automation platform remains secure and ready for what comes next.
Learn More
For detailed technical information, including information about CVEs that have been addressed, review the Puppet Core 8.18 release notes.
Release Notes Explore Puppet Core
Puppet Core 8.17 strengthens the security foundation of your infrastructure automation by updating critical components and reducing exposure to known vulnerabilities—helping teams stay compliant, lower risk, and maintain confidence in their automation pipelines without disrupting daytoday operations.
 Stronger Security, Built In
Stronger Security, Built In
Puppet Core 8.17 includes updates to several foundational dependencies to address recently disclosed security vulnerabilities. These updates help ensure Puppet remains a trusted part of your infrastructure, especially in environments with strict security and compliance requirements.
Key security enhancements include:
- Updated OpenSSL (3.0.19)
Addresses multiple highimpact CVEs, helping protect encrypted communications and sensitive data across your Puppet infrastructure. - Updated Ruby (3.2.10)
Includes security fixes that improve the resilience of the runtime used by Puppet, reducing exposure to known vulnerabilities. - Updated curl (8.18.0)
Resolves several security issues related to data transfer and network communication, improving the overall security posture of agents and services.
These updates are designed to be seamless—delivering improved protection without changing how you manage or operate Puppet.
Cleaner, More Maintainable Platform
Puppet Core 8.17 also removes legacy components that are no longer needed, helping streamline the platform and reduce longterm maintenance risk.
- Ruby API removed from leatherman
The removal of this deprecated API simplifies the codebase and aligns with modern, supported integration patterns. - Brotli and zstd removed from agent curl builds
These compression libraries have been removed from agent curl builds to reduce complexity and attack surface. This change does not impact the functionality of Puppet or PXP agents.
Why Upgrade?
If security, compliance, and platform stability are priorities for your organization, Puppet Core 8.17 provides important updates that help you:
- Reduce exposure to known vulnerabilities
- Stay aligned with modern security expectations
- Maintain a clean, supported automation foundation
Upgrading ensures you continue to receive the latest security improvements and platform updates from Puppet.
Puppet Edge is available now as a new capability for Puppet Core, extending automation, compliance, and governance capabilities beyond servers to encompass network and edge devices.
With available features like Playbook Runner that retains value from prior automation investments, consistent policy management across distributed systems, embedded visibility into device state, and seamless integration with Puppet workflows, organizations can apply the same trusted automation and governance used for servers to edge environments – achieving broader consistency and control across hybrid infrastructure estates.
Release Notes Explore Puppet Core
Puppet Core 8.16.0 is a security-focused release that delivers critical updates to keep your infrastructure automation protected and stable. While no new product features are introduced in this version, it includes important updates to several underlying components—including Thor, curl, REXML, OpenSSL, and the URI gem—to address recently disclosed CVEs.
This release highlights the value of using Puppet’s fully supported, enterprise-grade distribution rather than relying solely on community-maintained open source packages. With Puppet Core, customers benefit from proactive vulnerability monitoring, tested dependency updates, and timely security patches delivered as part of a predictable release cadence.
Key security updates include:
• Updated Thor gem to address CVE-2025-54314
• Updated curl to address CVE-2025-9086 and CVE-2025-10148
• Updated REXML gem for CVE-2025-58767
• Updated OpenSSL to resolve CVE-2025-9230 and CVE-2025-9232
• Patched URI gem for CVE-2025-61594
By staying current with Puppet Core, organizations ensure they remain protected from emerging vulnerabilities and continue receiving reliable, vendor-backed updates throughout the product lifecycle.
Release Notes Explore Puppet Core
September 10, 2025
This release implemented several updates to improve error messages and help prevent security vulnerabilities.
Improved Error Messages
Puppet now reports when binary data is found in the catalog. The error message indicates the manifest file and line number that caused the problem to assist with troubleshooting.
Security Fixes & Hardened Dependencies
libxslt removed – Resolves:
CVE-2025-7424
CVE-2025-7425.
On macOS, nokogiri was replaced with libxml-ruby to remove the libxslt dependency. If you require the nokogiri gem on macOS, please install it separately.
resolv gem shipped with Puppet agent was patched (note: although the vulnerability was patched, the Ruby and resolv gem version numbers did not change) - Resolves:
CVE-2025-24294.
Resolved Issues
Puppet Core 8.14.0 included a version of Ruby compiled against a version of glibc available only on SLES 15 systems using service pack 6 and later. For systems running SLES 15 with earlier service packs this caused ‘glibc not found’ errors. This was resolved by compiling Ruby against an older version of glibc.
Deprecations and removals
Support was removed for two end of life OS versions. The following are no longer available as Puppet Core agents:
- macOS 11 Big Sur (x86_64)
- macOS 12 Monterey (x86_64 and ARM)
For full details of what’s included in this release, see the Puppet Core docs: 8.15 release notes
Release Notes Explore Puppet Core
July 2025
We’re excited to announce the release of Puppet Core 8.14.0! This release strengthens the platform’s enterprise-grade resilience with improved documentation usability and hardened security updates.
Back to topAI-Powered Search for Documentation
The Puppet Core documentation now features an intelligent search experience powered by AI. Ask natural-language questions right from the docs homepage and get answers sourced from both current product documentation and the Perforce knowledge base. It's never been faster to find the answers you need.
 Back to top
Back to top
Security Fixes & Hardened Dependencies
Continuing our commitment to security and SLA-backed patching, this release includes critical updates to core components:
- net-imap upgraded to v0.3.9 – Resolves
- CVE-2025-43857
- curl upgraded to v8.14.1 – Resolves:
- CVE-2025-5025
- CVE-2025-4947
- CVE-2025-5399
- libxml2 upgraded to v2.14.5 – Resolves
- CVE-2025-6021 and others
Bug Fixes
We’ve resolved an issue where Ruby would recursively scan the entire lib directory due to a gemspec problem. This fix improves loading behavior for both puppet and facter gems.
Release Notes Explore Puppet Core
June 2025
Released June 2025, Puppet Core 8.13.0 delivers critical security updates and resolves key issues that improve platform reliability across environments, including enhanced behavior on Windows systems.
Back to topSecurity updates in this release
This release includes several important vulnerability patches to strengthen Puppet Core’s hardened foundation:
libxml2 updated to v2.13.8 to address CVE-2025-32415 and CVE-2025-3241
boost updated:
Patched v1.73.0 for AIX, Solaris, and Windows
Updated to v1.80.0 for all other platforms (CVE-2012-2677)
augeas patched to resolve CVE-2025-2588
rapidjson patched (via leatherman) to resolve CVE-2024-39684 and CVE-2024-38517
Bug Fixes
- Resolved Puppet Config Command Failure
Previously, puppet config would fail after a fresh Puppet gem install due to missing parent directories. The expected directory structure is now reliably created on first run. - Windows Service Logon Case Sensitivity Fixed
Puppet now treats Windows service logon accounts as case-insensitive. This prevents unnecessary Puppet service restarts caused by case mismatches in logon names.
Release Notes Explore Puppet Core
April 2025
No organization can afford the risk of unaddressed vulnerabilities — and with Puppet Core, we continue to prioritize reliability, resilience, and security in each release. Puppet Core 8.12.0 addresses 12 security vulnerabilities identified in third-party libraries, including seven with “critical” or “high severity” CVSS scores.
These vulnerabilities, which affect both Open Source Puppet and Puppet Core, present a range of risks, including credential leaks, crashes, and system instability due to memory handling and overflow issues. Additionally, this release includes enhanced error messaging, reducing confusion for custom Hiera lookups.
Back to topSecurity fixes in this release
Updated Third Party Components to Mitigate 12 Vulnerabilities
- Upgraded Ruby to version 3.2.8 to address:
- CVE-2025-27219
- CVE-2025-27220
- CVE-2025-27221
- Upgraded OpenSSL to version 3.0.16 to address:
- CVE-2024-13176
- CVE-2025-0306
- Upgraded Curl to version 8.12.0 to address:
- CVE-2025-0725
- CVE-2025-0665
- CVE-2025-0167
- Upgraded Libxml2 to version 2.13.6 to address:
- CVE-2025-24928
- CVE-2024-56171
- Upgraded Libxslt to version 1.1.43 to address:
- CVE-2024-55549
- CVE-2025-24855
Default Server Trust Updated
- The server setting is no longer defaulted to
puppet, preventing unintended trust relationships when running as an unprivileged user.- Addresses CVE-2024-9128
New in this release
Enhanced Error Messaging for Custom Backend Hiera Lookups
- Say goodbye to cryptic error messages! When using custom backends in Hiera, missing modules now trigger detailed errors identifying the affected module, enabling faster diagnosis and resolution.
Deprecated in this release
Puppet Core 7 EOL
- Puppet 7 is officially end of life. Upgrade to Puppet 8 to maintain support and access to the latest updates.
RELEASE NOTES LEARN MORE ABOUT PUPPET CORE
February 20, 2025
Digital threats continue to grow in frequency and complexity, and risk is growing across every phase of software development. Organizations need to adopt applications that are created and supported by trusted, reputable vendors offering SLAs that meet internal and external compliance requirements.
Back to topPuppet Core: Vendor-Backed, Secure & Stable
Perforce is excited to announce Puppet Core, an enterprise-ready platform built on the foundation of open source Puppet. Puppet Core delivers reliable, stable, and secure vendor-backed software with guaranteed SLAs to meet internal and external requirements for compliance.
Puppet Core is developed, maintained, and supported by Perforce, a trusted vendor for over 30 years to enterprise organizations around the globe. This means increased confidence in your software supply chain and not having to navigate the complexities and resource drain of building, maintaining, and certifying builds on your own.
Back to topPuppet Core is available immediately with commercial licenses for organizations needing more than 25 nodes.
Included in Puppet Core:
Puppet Core software builds are rigorously tested to the highest security standards, delivering performance and continuous operational resilience for critical infrastructure and applications.
- Hardened Puppet binaries housed in a secure repository
- Guaranteed SLAs for high and critical severity CVEs
- Core essential agents, including the latest downstream version
- Requests for fixes and vulnerabilities
- Training engagement with Certified Puppet Engineers, including guidance on Puppet Core resources and an introduction to Security Compliance Enforcement
- Security Compliance Enforcement, a premium feature for implementing and continuously maintaining alignment with CIS Benchmarks and DISA STIGs using policy as code
Always-On Audit Readiness
Puppet Core provides vendor-guaranteed SLAs, giving you regulatory compliance and "always-on" audit readiness. The Security Compliance Enforcement modules for Windows and Linux are pre-built modules maintained by Puppet, providing peace of mind that your infrastructure is in a continuous desired state and hardened against industry-recognized security baselines.
Back to topNew in this release:
- Added support for the following operating systems for Developer users:
- Fedora 41
- macOS 15
Puppet Edge
September 23, 2025
Extending the Power of Puppet to the Edge
We are excited to announce Puppet Edge, a new capability for Puppet Core and the Puppet Enterprise platform. Puppet Edge extends enterprise-grade automation, governance, and compliance to network peripherals and edge devices with the same trust and consistency you rely on for servers, VMs, and cloud. Puppet Edge preserves prior automation investments, reduces complexity, and enables secure, scalable infrastructure management across your entire hybrid infrastructure estate using a single, unified platform.
Included in Puppet Edge:
- Unified Automation – Extend Puppet automation to firewalls, network peripherals, POS systems, and other edge devices using a single, unified solution.
- Seamless Integration – Works with Puppet Core and the Puppet Enterprise platform to provide enterprise-grade governance across your entire hybrid infrastructure estate.
- Flexible Agent + Agentless Design – Utilize NETCONF and YANG, SSH, and WinRM to manage non-OS devices while continuing to benefit from the power of Puppet Agents for Linux and Windows servers.
- Consistent Policy Management – Apply configuration, security, and compliance standards across hybrid and edge environments.
- Playbook Runner premium module – Execute existing playbooks and ad-hoc commands from tools like Ansible® as tasks directly within Puppet, without additional orchestration tools or license costs.
- EdgeOps premium module – provides tools and content samples for managing Puppet Edge network devices with the Puppet Enterprise platform.
Puppet Enterprise Advanced customers also get access to:
- Workflows – enables imperative orchestration of edge devices. Workflows are designed to help simplify development and execution of IT operations automation. Power users can build and share complex workflows, allowing teammates to execute sophisticated orchestration without deep Puppet knowledge.
- Infra Assistant: code assist – enabling you to use AI to generate content to help manage your devices.
Contact the Puppet sales team for information about licensing network and edge devices.
Security Compliance Management (formerly Puppet Comply)
Reduce operational friction and improve assessment reliability
SCM Release Notes Demo Puppet Enterprise Advanced
Security Compliance Management (SCM) 3.8.0 is included with the Puppet Enterprise platform and helps teams continuously assess systems against recognized security benchmarks to reduce risk and demonstrate compliance. It replaces manual checks with consistent, auditable insight into where systems meet policy and where action is required.
Back to topWhat’s New
The 3.8.0 release focuses on reducing operational friction, improving reliability of compliance assessments, and enabling teams to keep benchmark content current without interrupting workflows.
Keep compliance assessments aligned without upgrade delays
SCM now supports applying updated assessment licensing independently of a full product upgrade, allowing teams to continue evaluating systems against current CIS Benchmark content even when upgrade timelines do not align. This helps prevent gaps in coverage and maintains continuity in reporting and audit readiness.
Resolve operational issues directly within the product
New self-service capabilities make it easier to identify and clear incomplete or stuck scans through the SCM console. This reduces reliance on manual intervention, improves data consistency, and helps maintain a clean and accurate view of assessment activity.
Improve reliability for long-running and complex assessments
Enhancements to scan behavior provide better handling of longer-running assessments, supporting more consistent and complete results across complex environments. This helps ensure that evidence collection remains dependable as infrastructure scale and diversity increase.
A more responsive and dependable user experience
Updates to request handling and system behavior improve overall console responsiveness, reducing interruptions during routine use and allowing teams to work more efficiently when reviewing results or managing assessments.
Stay aligned with current benchmark content
SCM includes updated CIS-CAT Pro Assessor components and benchmark content, ensuring that scans evaluate systems against the latest available CIS guidance. This helps maintain accuracy in compliance reporting and supports alignment with evolving standards.
Security and maintenance updates
Security Compliance Management 3.8.0 includes improvements to strengthen core components and reduce exposure to known risks. These updates focus on improving the resilience of the API layer, addressing findings from security testing, and ensuring underlying dependencies remain current and supported.
Together, these changes help reduce operational risk, improve platform stability, and support ongoing vulnerability management efforts.
Back to topDocumentation updates
Documentation has been expanded to support common operational needs, including guidance for custom certificate configuration, improved instructions for upgrading in restricted or air-gapped environments, and general enhancements to upgrade documentation clarity.
Back to topNext steps
Review the Security Compliance Management 3.8.0 release notes for detailed technical information and upgrade considerations. Plan your upgrade within the Puppet Enterprise platform to take advantage of improved operational efficiency, more reliable assessments, and up-to-date benchmark coverage.
SCM Release Notes Demo Puppet Enterprise Advanced
Security Compliance Management (SCM) 3.7.0 is included with the Puppet Enterprise platform and helps teams continuously assess systems against recognized security benchmarks to reduce risk and prove compliance. It replaces manual checks with consistent, auditable insight into where environments meet policy and where action is needed.
Back to topWhat’s New
The 3.7.0 release focuses on keeping compliance programs aligned with evolving environments while improving reliability and governance as scale increases.
Expanded benchmark coverage for modern environments
This release updates and extends CIS Benchmark coverage to include numerous additional operating systems, helping compliance teams keep pace as infrastructure evolves.
More consistent compliance assessments
Improvements to how assessments run within the platform provide steadier performance during scans, supporting reliable evidence collection across larger or more complex environments.
Greater control over user sessions and APIs
New centralized controls improve how user sessions and API access are governed, supporting stronger alignment with organizational security policies and reducing unnecessary exposure.
Security and maintenance updates
Security Compliance Management 3.7.0 includes multiple vulnerability remediations and dependency updates across core components. These updates are designed to reduce inherited risk, support ongoing vulnerability management efforts, and maintain a stable compliance platform as the environment changes. For full details, consult the release notes.
Back to topNext steps
Review the Security Compliance Management 3.7.0 release notes for detailed technical information. Plan your upgrade within the Puppet Enterprise platform to take advantage of expanded coverage, improved reliability, and stronger governance controls.
SCM Release Notes Demo Puppet Enterprise Advanced
We are excited to announce that Security Compliance Management (SCM) 3.6.0 is now available.
SCM is included with the Puppet Enterprise platform and helps teams continuously assess systems against recognized security benchmarks to reduce risk and prove compliance. It replaces manual checks with consistent, auditable insight into where environments meet policy and where action is needed.
What is New in Security Compliance Management 3.6.0
This release strengthens how assessments are run, expands the scope of benchmarks you can evaluate against, and closes several security gaps, making it easier to defend audit readiness while maintaining a hardened operational posture.
Broader Compliance Coverage Without Extra Complexity
Security Compliance Management 3.6.0 now includes the full set of CIS-CAT Pro Assessor benchmarks, including those not formally supported by SCM.
Why this matters:
- Teams can assess more systems and configurations against CIS guidance.
- Security and compliance leaders gain greater visibility into gaps that previously went unmeasured.
- Audit preparation becomes less about exceptions and more about evidence.
This change reduces blind spots and gives organizations more confidence that their compliance posture reflects real world environments.
Safer Execution That Lowers Operational Risk
This release changes how temporary files and installers are handled, removing reliance on the /tmp directory and automatically cleaning up outdated CIS-CAT Pro Assessors.
The outcome:
- A smaller attack surface during scans and upgrades.
- Less risk of leftover artifacts that could be misused or flagged during audits.
- Cleaner, more predictable runtime behavior in locked down or regulated environments.
For teams operating under strict security controls, these improvements reduce friction with internal security reviews and platform hardening standards.
Stay Current With Modern Platforms and Benchmarks
Support is now included for newer operating systems and refreshed benchmarks across Windows, Linux, and macOS.
This ensures:
- Newer platforms like Windows Server 2025, RHEL 10, and the latest macOS releases can be assessed as they enter production.
- Benchmark updates reflect current CIS guidance, not outdated controls.
- Compliance tooling keeps pace with infrastructure modernization efforts.
This alignment helps organizations move forward with upgrades while maintaining compliance.
Security Hardening Built Into the Platform
Multiple security fixes are included in this release, including changes that eliminate the possibility of remote execution during scans and address several CVEs across dependencies.
The business impact:
- Reduced exposure from known vulnerabilities.
- Fewer findings from internal security reviews.
- Greater trust in the compliance tooling itself as part of the security stack.
Why Upgrade to 3.6.0
Upgrade to Security Compliance Management 3.6.0 if you want to:
- Reduce audit and compliance blind spots with broader benchmark coverage.
- Lower operational and security risk during assessments.
- Maintain confidence as you adopt newer operating systems and platforms.
- Ensure your compliance tooling meets the same security standards you expect from the rest of your environment.
This release is about strengthening trust in your compliance process, from scan execution to audit reporting.
August 5th 2025
Perforce Puppet announces (effective February 5, 2026), the end of life (EOL) for:
- Comply 2.x, the legacy version of Security Compliance Management (SCM).
Future development will now focus exclusively on SCM 3.x, which offers greater reliability, reduced dependencies, and ongoing innovation.
Customers currently using older versions are encouraged to migrate to the latest releases to avoid disruption and ensure continued support. Active maintenance and migration assistance will be provided up to the EOL date, with an option for extended support available as a premium offering.
3.5 RELEASE NOTES 2.25.0 RELEASE NOTES
DEMO PUPPET ENTERPRISE ADVANCED
July 11, 2025
We are excited to announce that Security Compliance Management (SCM) 3.5.0 and 2.25.0 are now available.
SCM is included with PE and PE Advanced to enable organizations to quickly assess infrastructure configurations against CIS Benchmarks and DISA STIGs using the integrated CIS-CAT Pro Assessor from the Center for Internet Security (CIS).
Back to topNew in this release:
Flexible Java management
The Comply module used for SCM now includes the option to use a locally installed Java runtime, instead of the Java bundled with the CIS-CAT Pro Assessor.
- Toggle between using a compatible local Java installation or the bundled Java.
- When the locally-installed Java version is specified, the bundled Java is automatically removed to streamline your environment.
- If you choose to revert to the bundled Java, it is automatically reinstalled.
This enhancement is ideal for customers with specific Java version requirements and those looking to align with internal security and compliance policies.
Secrets management for Podman installs
Starting in version 3.5.0, Podman-based installations use a secrets management mechanism to handle passwords and other sensitive information.
CIS-CAT Pro Assessor updates
SCM 3.5.0 and 2.25.0 both include the CIS-CAT Pro Assessor v4.55.0, featuring important security fixes and numerous updates to operating system benchmarks.
Updated benchmarks:
- CIS Ubuntu Linux 24.04 LTS STIG Benchmark v1.0.0 (new)
- CIS Microsoft Windows Server 2022 Benchmark v4.0.0 (updated from v3.0.0)
- CIS Microsoft Windows 10 Enterprise Benchmark v4.0.0 (updated from v3.0.0)
- CIS Microsoft Windows 10 Stand-alone Benchmark v4.0.0 (updated from v3.0.0)
- CIS Microsoft Windows 11 Stand-alone Benchmark v4.0.0 (updated from v3.0.0)
- CIS Microsoft Windows Server 2019 Benchmark v4.0.0 (updated from v3.0.1)
- CIS Apple macOS 13.0 Ventura Benchmark v3.1.0 (updated from v3.0.0)
- CIS Microsoft Windows Server 2022 Stand-alone Benchmark v1.0.0 (new)
- CIS Red Hat Enterprise Linux 9 STIG Benchmark v1.0.0 (new)
- CIS Apple macOS 14.0 Sonoma Benchmark v2.1.0 (updated from v2.0.0)
- CIS Apple macOS 15.0 Sequoia Benchmark v1.1.0 (new)
- CIS SUSE Linux Enterprise 12 Benchmark v3.2.1 (updated from v3.2.0)
Removed benchmarks:
- CIS Apple macOS 11.0 Big Sur Benchmark v4.0.0
- CIS Oracle Linux 7 Benchmark v4.0.0
- CIS Red Hat Enterprise Linux 7 Benchmark v4.0.0
- CIS Red Hat Enterprise Linux 7 STIG Benchmark v2.0.0
- CIS CentOS Linux 7 Benchmark v4.0.0
- CIS Debian Linux 10 Benchmark v2.0.0
- CIS Ubuntu Linux 18.04 LTS Benchmark v2.2.0
RELEASE NOTES
SEE PUPPET ENTERPRISE ADVANCED IN ACTION
April 30, 2025
We’re excited to announce the release of Security Compliance Management (SCM) versions 3.4.0 and 2.24.0.
SCM is included with Puppet Enterprise (PE) and PE Advanced and enables organizations to quickly assess infrastructure configurations against CIS Benchmarks and DISA STIGs using the integrated CIS-CAT Pro Assessor from the Center for Internet Security (CIS).
Both releases have been updated with the latest version of the CIS-CAT Pro Assessor, enabling Puppet Enterprise customers to monitor compliance with the all operating system benchmarks supported by the Center for Internet Security (CIS).
Back to top
New in this release:
CIS-CAT Pro Assessor updates
SCM 3.4.0 and 2.24.0 include version 4.52.0 of the CIS-CAT Pro Assessor.
Updated benchmarks
- Apple macOS 12.0 Monterey v4.0.0
- Apple macOS 12.0 Monterey Cloud-tailored v1.1.0
- Apple macOS 14.0 Sonoma Cloud-tailored v1.1.0
- Microsoft Windows 11 Enterprise v4.0.0
- Microsoft Windows Server 2019 STIG v3.0.0
- Microsoft Windows Server 2022 STIG v2.0.0
- Red Hat 8 STIG v2.0.0
- SUSE Linux Enterprise 15 v2.0.1
- Ubuntu Linux 20.04 LTS v3.0.0
Removed benchmarks:
- CIS Microsoft Windows Server 2012 (non-R2) Benchmark v3.0.0
- Microsoft Windows Server 2012 R2 Benchmark v3.0.0
Java run-time environment update
The JRE included in the assessor bundle is updated to Amazon Corretto v8.442.06.1
Platform support for SCM
SCM can now be installed on the following operating systems:
- AlmaLinux 9
- Rocky Linux 9
- Oracle Linux 9
- Debian 12
Resolved issues
3.4.0 and 2.24.0
- Fixed an issue affecting the export service.
- Fixed an issue where scans showed success but reported 0% results due to an OS mismatch.
- Security fixes for a range of CVEs.
3.4.0 only
- Fixed an issue where the offline install bundle did not properly include the .modules directory.
RELEASE NOTES DEMO PUPPET ENTERPRISE
Aug. 16, 2024
This release of Security Compliance Management includes an enhancement that improves reliability, accuracy, and scalability of scheduled scans when onboarding new nodes to Puppet. Additionally, an update to the user experience improves flexibility by permitting the modification of key settings (including inventory refresh intervals and data retention settings) anytime versus only during installation, allowing for more efficient management.
This release also includes CIS Benchmark updates, fixes for a known issue, and an update to address a critical vulnerability in an open-source identity and access management (IAM) tool leveraged by Puppet.
(Release notes for the functionally equivalent Puppet Comply 2.22.0 can be found here.)
Back to topNew in this release:
- Dynamically target nodes for scheduled scans: This timesaving feature removes the manual effort of editing scheduled scans whenever new nodes are onboarded. Now, when scheduling scans in the Security Compliance Management Console, customers can target nodes dynamically by specifying the node groups to scan, so that scans run automatically on all nodes that belong to the specified node groups at the scheduled times.
- Configure the inventory refresh and data retention settings: This enhancement gives more flexibility and control to our customers. Previously, inventory refresh intervals and data retention settings were configurable only during the installation process. Now, to improve user experience, the Settings page in the Security Compliance Management Console allows customers to adjust these two settings at any time.
- Inclusion of CIS-CAT® Pro Assessor v4.43.0 (released July 11, 2024).
- Security Compliance Management is regularly updated with the latest version of the CIS-CAT Pro Assessor, which assesses system compliance with CIS Benchmarks to generate actionable insights.
- Added support for the latest CIS Benchmarks for the following operating systems:
- Apple macOS 12.0 Monterey Benchmark v3.1.0
- Apple macOS 13.0 Ventura Benchmark v2.1.0
- Microsoft Windows Server 2019 Stand-alone v2.0.0
- Oracle Linux 9 Benchmark v2.0.0
- Red Hat Enterprise Linux (RHEL) 9 Benchmark v2.0.0
Issues resolved in this release:
- Fixed a bug that could prevent node selection when creating an ad hoc desired compliance scan.
Security fixes in this release:
- Resolved the following CVE:
- Upgraded KeyCloak to v25 to address CVE-2023-2976.
RELEASE NOTES DEMO PUPPET ENTERPRISE
June 27, 2024
With this release of Security Compliance Management (formerly Puppet Comply), Puppet Enterprise users can now set their desired compliance defaults for each operating system (OS), saving valuable time when adding new nodes to a common OS.
We’ve added instructions for performing data backups and a guided tutorial for conducting ad hoc scans using the REST API available with Security Compliance Management. This release also includes CIS Benchmark updates, fixes for several known issues, and security updates.
Back to topNew in this release:
- Desired compliance can be set for operating systems. Any node added to that OS will automatically be assigned the default benchmark and profile you set for that OS.
- Added instructions on data backup: Security Compliance Management now includes instructions for backing up your data to make it easier to restore systems in a disaster recovery scenario.
- REST API tutorial: A new tutorial guides users through running an ad hoc scan in Security Compliance Management using the REST API added in 2.18.0.
- journald logging instructions: Added instructions on how to access relevant log files with the journald logging driver.
- Inclusion of CIS-CAT® Pro Assessor v4.42.0 (released May 30, 2024).
- Security Compliance Management is regularly updated with the latest version of the CIS-CAT Pro Assessor, which assesses system compliance with CIS Benchmarks to generate actionable insights.
- Added support for the latest CIS Benchmarks for the following operating systems:
- Debian Linux 12 Benchmark v1.0.1
- Microsoft Windows 11 Stand-alone Benchmark v3.0.0
- Microsoft Windows Server 2019 Benchmark v3.0.1
Issues resolved in this release:
- Fixed an issue that could prevent existing scheduled scans from running after migrating from Security Compliance Management version 2.x to 3.x.
- Fixed an issue where the search box on the exceptions page wouldn’t accept input.
- Fixed an issue that was causing macOS nodes to be listed as Darwin on the Inventory page, which prevented the desired compliance from being set for those nodes.
Security fixes in this release:
- Resolved the following CVEs:
- Updated braces to address CVE-2024-4068
- Updated KeyCloak to address CVE-2024-2961, CVE-2024-33599, CVE-2024-2700, CVE-2024-1132, CVE-2024-1249, CVE-2024-2419, CVE-2024-3656, GHSA-69fp-7c8p-crjr
- Updated oauth2-proxy to address CVE-2023-5363
RELEASE NOTES DEMO PUPPET ENTERPRISE
May 7, 2024
Starting with 3.0.0, Puppet Comply is now Security Compliance Management, and it’s included with Puppet Enterprise! Access it through the Security Compliance Management Console, exclusively in Puppet Enterprise to instantly gain valuable insight into the state of security of your Puppet estate.
Security Compliance Management retains all key features of Puppet Comply, including compliance assessment, monitoring, and reporting for configurations in your Puppet-managed infrastructure. Maintained and supported by Puppet, Security Compliance Management receives regular updates, just like Comply.
Automatic enforcement and remediation of hardened security baseline configurations is available in Security Compliance Enforcement (formerly Compliance Enforcement Modules), available as a premium feature for Open Source Puppet and Puppet Enterprise.
This release includes the latest CIS-CAT® Pro Assessor, support for the latest CIS Benchmarks for key operating systems, fixes for various issues, and resolutions for security vulnerabilities in third-party dependencies.
Back to topNew in this release:
- Puppet Comply is now Security Compliance Management
- Security Compliance Management is now included in the full Puppet Enterprise suite
- New installer wizard: The new Puppet Bolt-based installer for Security Compliance Management provides an easy wizard for installing, upgrading, and configuring Security Compliance Management in an agentless fashion via SSH.
- Inclusion of CIS-CAT® Pro Assessor v4.41.0 (released Apr. 25, 2024).
- Security Compliance Management is regularly updated with the latest version of the CIS-CAT Pro Assessor, which assesses system compliance with CIS Benchmarks to generate actionable insights.
- Added support for the latest CIS Benchmarks for the following operating systems:
- Debian Linux 11 Benchmark v2.0.0
- Microsoft Windows 10 Stand-alone Benchmark v3.0.0
- Microsoft Windows Server 2016 Benchmark v3.0.0
- Microsoft Windows Server 2019 Benchmark v3.0.0
- Microsoft Windows Server 2022 Benchmark v3.0.0
- Ubuntu Linux 18.04 LTS Benchmark v2.2.0
- Ubuntu Linux 22.04 LTS Benchmark v2.0.0
Issues resolved in this release:
- Fixed an issue where users could not change the desired compliance after changing the OS on a node.
Security fixes in this release:
- Resolved security vulnerabilities present in embedded, third-party dependencies of the CIS-CAT Pro Assessor v4.41.0:
- PostgreSQL updated to v42.7.2.
- xmlsec updated to v4.0.1.
- cxf-core-updated to v3.5.8.
- bouncycastle updated to v1.78.
RELEASE NOTES DEMO PUPPET ENTERPRISE ADVANCED
December 11, 2024
Usability and upgrade simplicity is at the core of this release of Security Compliance Management (SCM) in Puppet Enterprise and Puppet Enterprise Advanced, along with bug fixes, CVE patches, and new benchmarks to scan against.
See the benefits of the latest version of SCM faster with easier migration from 2.x to 3.x; use new APIs to get the insights your team needs faster; integrate scans into your CI/CD pipelines instead of modifying configurations; get rid of old assessor versions with a single task; and assess against the latest CIS Benchmarks with ease.
(Release notes for Puppet Comply 2.23.0 can be found here.)
Back to topNew in this release:
- Non-root support: Enables customers that don’t allow root access to servers to install SCM 3.3.0, aiding in the migration path from SCM 2.x.
- The Profiles API: Four new endpoints enable retrieval of information about SCM benchmark profiles, including:
- Retrieve a list of all available benchmark profiles.
- Retrieve details of a specific profile using its ID.
- Retrieve a list of custom profiles created by users.
- Retrieve details of a specific custom profile.
- The Custom Scan API: This endpoint API allows your team to create ad-hoc custom scans, which can be run with a custom profile or a profile and a benchmark.
- Run the
remove_assessor taskto remove old versions of the CIS-CAT® Pro Assessor that are no longer in use. - Inclusion of the CIS-CAT® Pro Assessor 4.47.0, allowing users to assess infrastructure baselines against the latest CIS Benchmarks, including:
- AlmaLinux OS 9 Benchmark v2.0.0
- Amazon Linux 2023 Benchmark v1.0.0
- Apple macOS 13.0 Ventura Benchmark v3.0.0
- Apple macOS 14.0 Sonoma Benchmark v2.0.0
- Debian Linux 12 Benchmark v1.1.0
- Microsoft Windows Server 2016 STIG Benchmark v3.0.0
- Rocky Linux 9 Benchmark v2.0.0
- SUSE Linux Enterprise 12 Benchmark v3.2.0
- Ubuntu Linux 24.04 LTS Benchmark v1.0.0
Issues resolved in this release:
- Fixed an issue where scans would not complete when running against machines running CIS-CAT® Pro Assessor versions 4.37.0 and later.
- Fixed an issue in SCM 3.2.0 that could result in containers for components and services failing to run due to exceeded
num_locks.
Security fixes in this release:
- Updated NGINX to 1.27.2 to address the following CVEs:
- CVE-2013-2028
- CVE-2021-23017
March 14, 2024
Secure enterprise IT relies on simple, sensible access to valuable data on your security and compliance posture. In the previous release, we introduced a new REST API to help users retrieve and use data from Puppet Comply. With 2.19.0, we're making those powerful insights even more accessible and actionable with two new API endpoints for Export and Inventory functions.
This release also includes an update to the CIS-CAT Pro® Assessor embedded in Puppet Comply, updated benchmark support for enterprise Windows, and regular fixes for known security vulnerabilities.
New in this release:
- Additions to the Comply API. Improved accessibility and efficiency of Comply functions by adding two new endpoints to the Comply API.
- Exports API: Create, retrieve, download, and delete exports of data from Puppet Comply.
- Inventory API: Initiate a Puppet Enterprise inventory sync.
- Inclusion of CIS-CAT Pro Assessor v4.39.0 (released Feb. 28, 2024).
- Comply is regularly updated with the latest version of the CIS-CAT Pro Assessor, which assesses system compliance with CIS Benchmarks to generate actionable insights.
- Updated support for CIS Benchmarks:
- Microsoft Windows 10 Enterprise v3.0.0
- Microsoft Windows 11 Enterprise v3.0.0
Security fixes in this release:
- Resolved security vulnerabilities present in embedded, third-party dependencies of the CIS-CAT Pro Assessor v4.39.0.
commons-compressupdated to v1.26.0
- Resolved CVE-2023-26159.
- Upgraded
follow-redirects-1.15.2dependency tofollow-redirects-1.15.4
- Upgraded
Dec. 13, 2023
With the debut of Puppet Comply 2.18.0, Puppet is thrilled to announce the immediate availability of a powerful REST API for Puppet Comply. This valuable new interface allows users to quickly retrieve data at scale from Comply to share among groups and enrich other tools in the stack.
The new API leverages Comply’s native scalability to support data extraction for up to 100,000 nodes, enabling simpler enterprise compliance reporting at the summary and detail levels. Puppet’s open, integrated approach ensures data consistency across teams and tech to unlock productivity through smoother collaboration. No matter how you manage compliance, Comply’s new API enables the transparency, accountability, and responsiveness auditors require – and creates a single window of deep compliance visibility.
Additionally, an updated CIS-CAT Pro Assessor and no fewer than 10 updated Center for Internet Security (CIS) Benchmarks help Comply users stay abreast of the latest security standards across operating systems. Updates for AlmaLinux, macOS 11 and 12, Oracle Linux, and RHEL 8, along with a brand-new benchmark for macOS 13, round out the growing list of supported CIS Benchmarks in Comply.
New in this release:
- Added a RESTful API for Puppet Comply.
- Included the CIS-CAT Pro Assessor v4.36.0 (released Nov. 2023).
Benchmarks updated in this release:
- CIS AlmaLinux OS 8 Benchmark v3.0.0
- CIS Apple macOS 11.0 Big Sur Benchmark v4.0.0
- CIS Apple macOS 11.0 Big Sur Benchmark v4.0.0
- CIS Apple macOS 12.0 Monterey Benchmark v3.0.0
- CIS Microsoft Windows Server 2012 (non-R2) Benchmark v3.0.0
- CIS Microsoft Windows Server 2012 R2 Benchmark v3.0.0
- CIS Microsoft Windows Server 2016 STIG Benchmark v2.0.
- CIS Oracle Linux 8 Benchmark v3.0.0
- CIS Red Hat Enterprise Linux 8 Benchmark v3.0.0
- CIS Rocky Linux 8 Benchmark v2.0.0
Benchmarks added in this release:
- CIS Apple macOS 13.0 Ventura Benchmark v2.0.0
Benchmarks removed in this release:
- CIS Apple macOS 10.15 Catalina Benchmark v3.0.0
Issues resolved in this release:
- Node results page shows compliance score without exceptions.
- Security fixes.
Nov. 2, 2023
Comply receives another boost in supported node count with support for a maximum of 100,000 nodes. The latest CIS-CAT Pro® Assessor from The Center for Internet Security (CIS) has been integrated, with updates to Ubuntu Linux benchmarks and removal of several older benchmarks. The CIS-CAT Pro Assessor for MacOS now contains embedded Java.
New in this release:
- Scalability improvements for enterprise-grade compliance management.
- Node count increased to 100,000.
- Embedded JRE for MacOS eliminates the need for a separate Java install.
- Included the CIS-CAT Pro Assessor v4.34.0.
- Updated support for CIS Benchmarks for Ubuntu Linux 20.04 LTS Benchmark v2.0.1.
- Removed support for older CIS Benchmarks.
Issues resolved in this release:
- Resolved several reported issues.
Sept. 21, 2023
Large enterprises continue to receive attention from the Comply engineering team. To give IT teams an even broader degree of decision-making power over their infrastructure compliance, Comply 2.16.0 features dramatic increases to supported node count, continuing a trend from recent Comply releases.
Comply 2.16.0 also integrates the latest CIS-CAT Pro® Assessor from The Center for Internet Security (CIS), with updates to Ubuntu Linux and Debian Linux benchmarks.
New in this release:
- Scalability improvements for enterprise-grade compliance management.
- Node count increased to 75,000.
- Updated support for CIS Benchmarks.
- Included the CIS-CAT Pro Assessor v4.33.0.
- Resolved several reported issues.
Aug. 10, 2023
Compliance scalability continues to be a challenge for enterprise organizations, which means it's a major focus for the Comply engineering team. Following the notable increases to supported node count in 2.14.0, Comply 2.15.0 has also now dramatically improved export functionality to allow users to export raw data results for up to 50,000 nodes.
Leaning into our valued partnership with the Center for Internet Security (CIS), Comply 2.15.0 also integrates the CIS-CAT Pro® Assessor v4.32.0 with updates to MacOS benchmarks.
New in this release:
- Scalability improvements for enterprise-grade compliance management.
- Raw data export support increased to 50,000 nodes.
- Updated support for CIS Benchmarks.
- Included the CIS-CAT Pro Assessor v4.32.0 (July 2023) with benchmark coverage for Apple macOS 11 v3.1.0 and 12 v2.1.0.
- Resolved several reported issues.
Issues resolved in this release:
- Fixed an issue where inventory sync made paging requests without ordering, leading to ingest retrieving fewer hosts than expected. Also improved database efficiency and accuracy.
- Fixed an issue where filters in the 'Compliance over time' chart could display missing days.
- Fixed an issue where discrepancies appeared between active exceptions counts on the Comply dashboard and the exceptions page.
One of the most frequently requested features for Puppet Comply has been to support different user roles. Comply 2.14.0 adds role-based access control, enabling you to designate three roles based on access need. We also increased node support in this release so you can confidently stretch your compliant infrastructure even further.
We also updated integration with the latest CIS-CAT Pro Assessor and numerous benchmarks, and resolved a few vulnerabilities in this release.
- Identity and access management
- RBAC integration with three default roles: Admin, operator, and viewer
- Support for importing from LDAP
- Scalability improvements for enterprise-grade compliance management
- Node count increased to 50,000
- Updated support for numerous CIS Benchmarks
- Included the CIS-CAT Pro Assessor v4.30.0
- Addressed multiple CVEs
- Resolved an issue when scanning a node in the Darwin family (Mac OS X/macOS)
Effective compliance requires good visibility. Comply’s dashboard has received significant enhancements in 2.13.0, bringing new clarity to your compliance standing. Compliance statistics are reported on servers that live on-prem or in the cloud. Search and subset node views based on server attributes, such as name or operating system, and drill down to key focus areas to quickly identify areas where action is needed.
As always, we called upon our unique partnership with the Center for Internet Security (CIS) to power Comply with the latest CIS-CAT Pro Assessor (v4.28.0), and we’ve incorporated the latest benchmarks and standards so your compliance has the most up-to-date expert standards built in.
We even had time to fix a couple of nagging little bugs from prior releases, address a few CVEs, and boost performance.
- Redesigned dashboard with new graphs, node count and exceptions, and accessible action steps
- Improved performance and scalability
- Included the CIS-CAT Pro Assessor v4.28.0
- Updated benchmark support
- Resolved multiple vulnerabilities
Security Compliance Enforcement (formerly CEM)
Expanded platform coverage and improved reliability for compliance enforcement
SCE for Linux Release Notes Demo Security Compliance Enforcement
Security Compliance Enforcement (SCE) helps you automatically maintain systems aligned to recognized security benchmarks across your Linux and Windows environments without manual effort.
Available within Puppet Core and Puppet Enterprise Advanced, this release extends that coverage to Red Hat Enterprise Linux 10 and improves the consistency of everyday enforcement.
Back to topWhy Upgrade
- Expand compliance coverage to new environments
Support for Red Hat Enterprise Linux 10, AlmaLinux 10, Oracle Linux 10, and Rocky Linux 10 allows teams to apply established compliance standards as they adopt newer operating systems. - Improve reliability of automated enforcement
Fixes in this release reduce unintended configuration changes and execution failures, leading to more predictable Puppet runs. - Strengthen audit readiness with aligned benchmarks
Updated support for CIS Benchmarks on newly supported platforms helps ensure systems are configured consistently against recognized standards. - Reduce operational risk from configuration drift and errors
Resolved issues address conditions that previously caused incorrect configurations or failures, lowering the likelihood of compliance gaps or remediation delays.
What’s New
- Support for RHEL 10 with CIS Benchmark enforcement
SCE now supports Red Hat Enterprise Linux 10, enabling enforcement of CIS Benchmark version 1.0.1 for Server Levels 1 and 2. This extends compliance coverage to newer infrastructure without requiring changes to existing enforcement approaches. - Improved reliability of configuration management behaviors
An issue where the rsyslog configuration file was overwritten on every Puppet run has been resolved. This ensures that configurations respect defined control settings and reduces unnecessary changes across environments. - More stable file integrity monitoring setup
Updates to the Advanced Intrusion Detection Environment (AIDE) integration resolve incompatibilities with newer versions, preventing initialization failures and enabling consistent file integrity monitoring on supported systems. - Aligned and accurate reference documentation
Reference information has been corrected to reflect supported profiles, helping teams rely on consistent guidance when implementing and validating compliance configurations. - Deprecation of unsupported operating systems
RHEL 7 is end of life and is no longer supported
Together, these changes help reduce exposure to misconfiguration, improve audit confidence, and ensure more reliable enforcement over time.
Back to topNext Steps
- Review the full release notes for additional context and known issues
- Upgrade to SCE for Linux 2.7.0 to take advantage of expanded platform support and reliability improvements
SCE for Linux Release Notes Demo Security Compliance Enforcement
We are excited to announce that Security Compliance Enforcement (SCE) for Linux 2.6.0 is now available.
SCE is included with Puppet Core and Puppet Enterprise Advanced and enables organizations to easily and continuously align configurations to popular security baselines from the Center for Internet Security (CIS) and U.S. Defense Information Systems Agency (DISA). Using SCE, Puppet minimizes risk by shrinking attack surfaces on infrastructure at scale.
New In This Release:
Ubuntu 24.04 support
Security Compliance Enforcement for Linux now supports Ubuntu 24.04, enabling teams to adopt the latest Ubuntu LTS while maintaining continuous compliance with CIS Benchmarks at Server Levels 1 and 2.
Ubuntu is widely used for cloud infrastructure, platform services, and Kubernetes nodes. With this release, Puppet customers can enforce the same security baselines across their newest Ubuntu deployments as the rest of their Linux estate, without slowing OS upgrades or introducing compliance risk.
Better visibility into enforcement activity
This release improves day-to-day insight into compliance enforcement. More detailed enforcement information is now available directly in the Puppet agent run, along with improved visibility into mounted file systems to reduce configuration blind spots.
Reliability and usability improvements
This release incorporates bug fixes and operational improvements that make enforcement more reliable and easier to operate. Updates improve logging clarity, reduce troubleshooting friction, and address edge cases that could impactenforcement consistency in real world environments.
Access the update: Customers with an active SCE subscription can download the latest version of the module from the Forge.
SCE FOR WINDOWS RELEASE NOTES DEMO SECURITY COMPLIANCE ENFORCEMENT
We are excited to announce that Security Compliance Enforcement (SCE) for Windows 2.2.0 now available.
SCE is included with Puppet Core and Puppet Enterprise Advanced and enables organizations to easily and continuously align configurations to popular security baselines from the Center for Internet Security (CIS) and U.S. Defense Information Systems Agency (DISA). Using SCE, Puppet minimizes risk by shrinking attack surfaces on infrastructure at scale.
New In This Release:
SCE now supports the CIS Microsoft Server 2025 Benchmark v1.0.0, Server Level 1.
SCE FOR LINUX RELEASE NOTES DEMO SECURITY COMPLIANCE ENFORCEMENT
September 30, 2025
We are excited to announce that Security Compliance Enforcement (SCE) for Linux 2.5.0 is now available.
SCE is included with Puppet Core and Puppet Enterprise Advanced and enables organizations to easily and continuously align configurations to popular security baselines from the Center for Internet Security (CIS) and U.S. Defense Information Systems Agency (DISA). Using SCE, Puppet minimizes risk by shrinking attack surfaces on infrastructure at scale.
New In This Release:
You can now use SCE to enforce updated CIS Benchmarks on the following four operating systems:
- Red Hat Enterprise Linux (RHEL) 9
- AlmaLinux 9
- Oracle Linux 9
- Rocky Linux 9
The CIS Benchmarks are updated from v1.0.0 to v2.0.0, Server Levels 1 and 2.
Refer to the release notes for detailed information about controls that were added, changed, or removed.
Access the updates: Customers with an active SCE subscription can download the latest version of the module from the Forge.
SCE FOR LINUX RELEASE NOTES DEMO SECURITY COMPLIANCE ENFORCEMENT
June 24, 2025
We’re excited to announce that Security Compliance Enforcement (SCE) for Linux version 2.4.0 is now available.
SCE is included with Puppet Core and Puppet Enterprise Advanced and enables organizations to easily and continuously align configurations to popular security baselines from the Center for Internet Security (CIS) and U.S. Defense Information Systems Agency (DISA). Using SCE, Puppet minimizes risk by shrinking attack surfaces on infrastructure at scale.
Back to topNew in this release:
You can now use SCE to enforce DISA STIG controls on RHEL 9 systems. This extends the existing support for STIG compliance on RHEL 7 and 8, helping even more organizations meet stringent security requirements.
Developed by the U.S. Defense Information Systems Agency (DISA), the Security Technical Implementation Guides (STIGs) are required by many government agencies and supporting contractors and are also often adopted by other organizations wishing to implement strict security baselines.
Access the updates: Customers with an active SCE subscription can download the latest version of the module from the Forge.
SCE FOR WINDOWS RELEASE NOTES DEMO SECURITY COMPLIANCE ENFORCEMENT
February 25, 2025
We’re excited to announce that Security Compliance Enforcement (SCE) for Windows version 2.1.0 is now available.
SCE is included with Puppet Core and Puppet Enterprise Advanced and enables organizations to easily and continuously align configurations to popular security baselines from the Center for Internet Security (CIS) and U.S. Defense Information Systems Agency (DISA). Using SCE, Puppet minimizes risk by shrinking attack surfaces on infrastructure at scale.
Back to topNew in this release:
New CIS Benchmarks supported in sce_windows v2.1.0:
- CIS Microsoft Server 2022, v3.0.0, Member Server, Level 1.
- CIS Microsoft Server 2019, v3.0.0, Member Server, Level 1.
- CIS Microsoft Server 2016, v3.0.0, Member Server, Level 1.
- CIS Microsoft Windows 10 Enterprise, v3.0.0, Corporate Enterprise, Level 1.
Access the updates: Customers with an active SCE subscription can download the latest version of the module from the Forge.
SCE FOR LINUX RELEASE NOTES DEMO SECURITY COMPLIANCE ENFORCEMENT
December 10, 2024
This release of Security Compliance Enforcement (SCE) for Linux discontinues support for CentOS 7, which reached EOL in June 2024. Also included are issue resolutions to help ensure that chrony time synchronization works as designed on Ubuntu Linux 20.04.
Back to topUpdated in this release:
- Discontinued support for CentOS 7: The end of community support for CentOS 7 was announced in December 2020, and it reached EOL in June 2024. This release of SCE for Linux discontinues support for the operating system.
- If you plan to transition to a different OS with a different CIS Benchmark, you might have to update the configuration to avoid operational issues.
Issues resolved in this release:
- Resolved several issues from SCE for Linux 2.2.1 related to chrony time synchronization on Ubuntu Linux 20.04. Head to the full SCE for Linux 2.3.0 release notes for a full list of issues resolved.
- Resolved an issue related to the GnuTLS Transport Layer Security Library in which the exec resource
sce_gnutls_versionwas unnecessarily enforced during each Puppet run.
SCE FOR LINUX RELEASE NOTES DEMO SECURITY COMPLIANCE ENFORCEMENT
October 15, 2024
This release of Security Compliance Enforcement (SCE) for Linux enables users to enforce a greater degree of security on Ubuntu Linux 22.04 using CIS Benchmark Level 2 profiles. Users of DISA STIG controls can meet an updated standard for Red Hat Enterprise Linux (RHEL) 8.
Back to topNew in this release:
- Added support for the latest CIS Benchmarks for the following operating systems:
- Ubuntu Linux 22.04, v2.0.0, Level 2 – Server
- Ubuntu Linux 20.04, v2.0.1, Level 2 – Server
- Added support for updated DISA STIG on the following operating system:
- Upgraded RHEL 8 STIG from Version 1, Release 11 to RHEL 8 STIG Version 1, Release 14.
- Hiera Automatic Parameter Lookup (APL) can now be used to override any parameter implemented by a resource used by SCE for Linux.
- Usability improvements were implemented for the Bolt plan
linux_users_and_groups, which is used to enforce user-specific and group-specific security settings on all applicable users and groups in a system.
Issues resolved in this release:
- Resolved an issue related to audit log file permissions, bringing them in line with the management method for all other files in the
/var/log/auditdirectory. - Resolved a password issue on RHEL 8 operating systems.
- Resolved compilation errors sometimes seen by users running SCE for Linux with Puppet Enterprise 2021.7.8 and 2021.7.9.
- Resolved an issue that was causing scan failures related to the Gnome Desktop Manager (GDM) banner message.
RELEASE NOTES ADD SECURITY COMPLIANCE ENFORCEMENT
Aug. 13, 2024
This release of Security Compliance Enforcement for Linux allows for enforcement of security hardening controls on a broader range of operating systems, including enforcement of the latest CIS Benchmarks on key OSes. Other updates let you fine-tune which security controls are enforced without splitting them across multiple configurations.
Back to topNew in this release:
- Added support for the latest CIS Benchmarks for the following operating systems:
- CIS AlmaLinux 9 Benchmark v1.0.0 is now supported at Server Levels 1 and 2.
- CIS Rocky Linux 9 Benchmark v1.0.0 is now supported at Server Levels 1 and 2.
- CIS Ubuntu 22.04 Benchmark v2.0.0 is now supported at Server Level 1.
- CIS RHEL 7 Benchmark v4.0.0 is now supported at Server Levels 1 and 2.
- CIS Oracle Linux 7 Benchmark v4.0.0 is now supported at Server Levels 1 and 2.
- Increased flexibility when specifying which CIS or STIG controls to enforce. Starting with 2.1.0, you can apply both the
onlyandignorekeys in a single configuration file. For example, if you have a list of 100 controls and use theonlykey to select 50 of them, you can then use theignorekey to exclude certain controls from those 50, giving you more precise control over which security rules are enforced.
Issues resolved in this release:
- Resolved an issue that generated error messages about dependency cycles when configuring custom firewall rules.
- Resolved an issue where specified audit permissions were applied only to
.conffiles in theetc/auditdirectory, rather than all configuration files in theetc/auditdirectory and subdirectories. - Fixed a defect that could disrupt SSH connectivity on some nodes.
- Fixed an audit rule issue that caused Puppet run failures in rare circumstances. Now, if the
findcommand fails, error messages are sent to thepuppetserverlog, but the Puppet run continues and other controls are enforced.
WINDOWS RELEASE NOTES LINUX RELEASE NOTES
May 7, 2024
New name, same great enforcement! Starting with 2.0.0, Compliance Enforcement Modules (CEM) is now Security Compliance Enforcement. It’s still a premium feature for Open Source Puppet and Puppet Enterprise that enforces secure configurations aligned to CIS Benchmarks and DISA STIGs — and it’s still created and supported by Puppet.
But the name’s not the only thing that’s changed. Security Compliance Enforcement 2.0.0 for Windows and Linux includes important updates to supported operating systems (including support for Ubuntu 20.04) and bug fixes to keep your infrastructure configurations aligned to security recommendations.
As part of the name change, the modules are now available on the Puppet Forge as sce_linux and sce_windows. If you have an active subscription to the Compliance Enforcement Modules (CEM), you are automatically granted access to the Security Compliance Enforcement modules.
New in these releases:
Security Compliance Enforcement for Linux 2.0.0
- Compliance Enforcement/Compliance Enforcement Modules/CEM for Linux is now Security Compliance Enforcement for Linux
- Added support for the latest CIS Benchmarks for the following operating systems:
- Red Hat Enterprise Linux 8 (CIS Benchmark v3.0.0 Levels 1 and 2)
- Oracle Enterprise Linux 8 (CIS Benchmark v3.0.0 Levels 1 and 2)
- Alma Linux 8 (CIS Benchmark v3.0.0 Levels 1 and 2)
- Rocky Linux 8 (CIS Benchmark v2.0.0 Levels 1 and 2)
- Ubuntu 20.04 (CIS Benchmark v2.0.1 Level 1)
Security Compliance Enforcement for Windows 2.0.0
- Compliance Enforcement/Compliance Enforcement Modules/CEM for Windows is now Security Compliance Enforcement for Windows
Security fixes in these releases:
- Security Compliance Enforcement for Linux and Security Compliance Enforcement for Windows now support the latest versions of their respective Puppet module dependencies.
- Several bug fixes in both Security Compliance Enforcement for Linux and Security Compliance Enforcement for Windows.
Puppet is excited to announce the immediate availability of Puppet CEM for Linux v1.9.0, featuring valuable added capabilities for enterprise customers.
Configuration drift is often cited by experts as a leading cause of security incidents and failed audits. Puppet’s Compliance Enforcement Modules (CEM) identify and quickly resolve configuration drift within infrastructure using policy-as-code (PaC) and are available for numerous editions of Windows and Linux.
CEM for Linux v1.9.0 incorporates support for the Center for Internet Security (CIS) benchmarks for two additional operating systems: Red Hat Enterprise Linux (RHEL) 9 and Oracle Linux 9, to ensure that these popular operating systems remain configured according to security policy. Both Level 1 and Level 2 benchmarks are supported.
CIS Level 1 benchmark profiles cover base-level configurations that are easier to implement and have minimal impact on business functionality. Level 2 benchmark profiles are intended for high-security environments and require more coordination and planning to implement with minimal business disruption.
Organizational efficiency gets a boost thanks to an improved auditing process which permits running a single Puppet Bolt® plan that includes up to 40 audit tasks to verify the configuration on one or more specified nodes.
Added
- Introduced support for the RHEL 9 operating system. You can now enforce the Center for Internet Security (CIS) RHEL 9 Benchmarks, Levels 1 and 2.
- Introduced support for the Oracle Linux 9 operating system. You can now enforce the Center for Internet Security (CIS) Oracle Linux 9 Benchmarks, Levels 1 and 2.
- The Bolt plan, run_audit, can be run with up to 40 audit tasks on one or more specified nodes to verify their configuration. The Bolt log file provides a list of audited controls and detailed results.
Changed
To help ensure compatibility between CEM for Linux and Puppet 8, the range of supported versions for the Puppet Labs® firewall module was changed. The firewall module must be at version 5.0 or later, but earlier than 6.0.
Sept. 28, 2023
Keep your configurations consistent and compliant at scale with regular updates to Compliance Enforcement Modules (CEM), available in Puppet Comply. This release features updated support for STIG benchmarks for Red Hat Enterprise Linux (RHEL) 7 and 8 along with a slew of updates to improve the user experience.
New in this release:
- Updated support for STIG benchmark to Version 3 Release 12 (V3R12) for RHEL 7.
- Updated support for STIG benchmark to Version 1 Release 11 (V1R11) for RHEL 8.
Issues resolved in this release:
- Regular bug fixes (see full release notes above).
Aug. 22, 2023
Staying aligned with the most up-to-date benchmarks from the Center for Internet Security (CIS) is the best way to ensure that you’re benefitting from the latest security recommendations.
Puppet’s Compliance Enforcement Modules (CEM) simplify the task of keeping your Puppet Enterprise-managed nodes in continuous compliance with recent benchmark releases for popular versions of Microsoft Windows and Linux.
New in this release:
- Added enforcement for the Center for Internet Security (CIS) Benchmark v2.0.0 for the following Windows operating systems:
- Microsoft Windows 10 Enterprise
- Microsoft Windows Server 2019
- Microsoft Windows Server 2016
- Enhanced upgrade documentation to ensure a smooth transition to version 1.5.0.
With CEM for Windows, you can bring your Puppet Enterprise-managed nodes into compliance with the CIS Benchmark for Windows Server 2022, Windows Server 2019, Windows Server 2016 and Windows 10. The expanded support in CEM for Windows 1.4, coupled with the existing broad coverage in CEM for Linux, allows you to enforce CIS Benchmark compliance across your Windows and Linux infrastructure.
- Added enforcement for the Center for Internet Security (CIS) Microsoft Windows Server 2022 Benchmark v2.0.0
- cem_windows no longer supports the use of legacy configuration as of this update. cem_windows is no longer compatible with configurations that were used before v1.1.0. Please update any legacy configuration to the current standard of configuring cem_windows
Continuous Delivery (Formerly CD4PE)
CD Release Notes Demo Puppet Enterprise Advanced
Continuous Delivery (CD) 15.5.0 helps teams test, promote, and deploy Puppet code across environments with more consistency and control, reducing manual effort and improving release discipline within the Puppet Enterprise ecosystem.
Continuous Delivery is included within the Puppet Enterprise platform, with advanced Impact Analysis capabilities available through Puppet Enterprise Advanced.
Back to topWhy Upgrade
This release strengthens platform security, improves delivery visibility, and adds controls that support more reliable and audit-ready operations. It is especially relevant for teams using proxied source control integrations, GitLab or Azure DevOps workflows, or advanced Impact Analysis capabilities.
Improve governance
New controls for webhook routing and session timeout management help teams apply clearer operational guardrails around infrastructure change.
Reduce security risk
This release adds CSRF protection, tightens authorization, and includes broad dependency and vulnerability updates to strengthen the platform baseline.
Increase delivery confidence
Updates to Pipelines as Code, Impact Analysis behavior, and data visibility improve the quality of information teams use to review and approve changes.
Stay aligned with current platforms
Support for Amazon Linux 2023 and an updated Postgres base image help keep the delivery platform current and operationally sound.
Back to topWhat’s New
Better control over integrations and access
A new webhook routing option helps customers support proxied environments, while an idle session timeout reduces the risk of unattended console sessions.
More focused Impact Analysis
Teams can now exclude nodes with no catalog resources in PuppetDB from Impact Analysis results, helping reduce noise and improve review quality. Advanced Impact Analysis capabilities remain available through Puppet Enterprise Advanced.
Clearer VCS visibility
Azure DevOps pipeline summaries now show the initiating user's display name instead of an ID. GitLab commit status updates are also handled more consistently, making pipeline activity easier to follow.
Broader support and smoother upgrades
This release adds support for Amazon Linux 2023, updates the Postgres base image, and automatically performs a database dump and restore during upgrade to support that change.
Back to topSecurity and Maintenance Updates
Continuous Delivery 5.15.0 delivers meaningful hardening beyond routine maintenance. It restricts access to sensitive user data, closes an authorization bypass in the GraphQL query path, and adds CSRF protection to sensitive account-related endpoints. It also updates a broad set of dependencies to address published vulnerabilities, helping customers reduce exposure and maintain healthier platform hygiene over time.
Back to topNext Steps
Review the upgrade guidance and full release notes, then plan your move to Continuous Delivery 5.15.0 within your Puppet Enterprise environment.
We are pleased to announce Continuous Delivery 5.14.0 and 4.39.0 are now available. These latest updates allow you to deliver changes with greater confidence, clearer diagnostics, and stronger security.
5.14.0 Release Notes
4.39.0 Release Notes
5.14.0: Improved Usability, Security, and Reliability
Version 5.14.0 introduces improvements for Puppet Enterprise (PE) and PE Advanced that make configuration issues easier to diagnose, strengthen account security, and increase workflow reliability across enterprise environments.
Usability and configuration improvements
- Clearer in app error messaging makes CORS and browser level issues easier to diagnose, reducing troubleshooting time for teams configuring new environments.
- Strengthened password policies improve account security by enforcing a minimum of 12 characters plus uppercase, lowercase, numeric, and special character requirements.
Platform and tooling updates
- Updated puppet dev tools image now includes PDK 3.6.1, aligned with Puppet 8 and Ruby 3.x.
- Customers using Puppet 7 and Ruby 2.7 can continue using the puppet7 image with PDK 3.4.1.
Fixes that eliminate delivery friction
- Impact Analysis now reports resource changes correctly for previously affected data types and returns clear errors for oversized titles.
- Corrected pipeline status links ensure accurate reporting back to version control providers.
- Azure DevOps Server integration now correctly handles previously truncated host URLs, restoring reliable repository linking.
Security updates
- This release includes fixes for CVE 2026-21452, CVE 2025-68161, CVE 2024-49761, CVE 2025-68973, CVE 2025-6020, and CVE 2025-13465.
Learn more
See the full technical details in the release notes:
CD 4.39.0: Maintenance Enhancements for Customers Still on 4.x
While customers are encouraged to upgrade to CD 5.x, version 4.39.0 delivers important maintenance improvements.
Platform support alignment
- Updated puppet dev tools image adds PDK 3.6.1 for Puppet 8 compatibility, while still providing a Puppet 7 option through the puppet7 image with PDK 3.4.1.
Fixes
- Impact Analysis improvements mirror those in 5.14.0, addressing incorrect reporting of resource changes and improving validation for oversized titles.
Security updates
- Includes fixes for CVE 2026-21452, CVE 2025-68161, CVE 2025-68973, CVE 2025-6020, and CVE 2025-13465.
Learn more
See the full technical details in the release notes:
Important Reminder: CD 4.x Approaching End of Life
Continuous Delivery 4.x reaches end of life on February 5, 2026. Customers should plan their upgrade to the 5.x series to maintain support, receive security updates, and benefit from the latest features.
August 5th 2025
Puppet by Perforce announces (effective February 5, 2026), the end of life (EOL) for:
- Continuous Delivery (CD) version 4.x
Future development will now focus exclusively on CD 5.x and which offers greater reliability, reduced dependencies, and ongoing innovation.
Customers currently using older versions are encouraged to migrate to the latest releases to avoid disruption and ensure continued support. Active maintenance and migration assistance will be provided up to the EOL date, with an option for extended support available as a premium offering.
DEMO PUPPET RELEASE NOTES 5.3 RELEASE NOTES 4.29
Feb. 8, 2024
We’re thrilled to share a new release for Continuous Delivery for Puppet Enterprise that will help you gain greater control of pipeline creation, as well as a new reporting function that will show the impact of Puppet across your organization. We’ve listened to your feedback to improve functionality and visibility in this latest release.
New for this release:
- APIs for Automation: You wanted to automate end-to-end workflows, and now public APIs will allow you to automate connecting your Continuous Delivery for Puppet Enterprise installation to change management tools (e.g. Remedy). Create new pipelines and edit existing ones in your workspace — easily enabling you to add modules and repositories.
- Activity Report: We’ve added a new activity report that shows the value Puppet Enterprise is providing to your organization across all instances. You can now specify the time saved per task and per plan, which will help visualize the value Puppet is providing for key workflows.
- Personal access token management. You can now create authentication tokens to allow a user to enter their credentials once, then receive an alphanumeric token to access different services or parts of the system infrastructure. To manage personal access tokens, see Manage personal access tokens.
- OpenAPI support. You can now fetch data and automate your workflows with the Continuous Delivery for Puppet Enterprise REST API. To get started using Continuous Delivery for Puppet Enterprise public APIs, see REST API.
- Value reporting. You can now view activity values across all the Puppet Enterprise (PE) instances integrated within a workspace in the Activity report. To view your activity in Continuous Delivery for Puppet Enterprise, see Activity reporting.
- Refreshed Continuous Delivery for Puppet Enterprise pipelines UI. The Continuous Delivery for Puppet Enterprise pipelines pages have a refreshed appearance.
- Generate new SSL certificates. Added a cd4peadm::regen_certificates plan to generate new SSL certificates for the app, using the current configuration. After running this plan, usecd4peadm::apply_configuration to upload the new certificates to Continuous Delivery for Puppet Enterprise.
Security fixes in this release:
- CVE-2023-39325. Updated several direct and indirect dependencies to address this vulnerability.
Nov. 30, 2023
This release of Continuous Delivery for Puppet Enterprise (CD4PE) touts performance improvements and enhancements to Impact Analysis, a key feature that enables a powerful added layer of visibility to help you preview the potential impact of changes to your code before deploying.
New in this release:
- Impact Analysis enhancements: It is now possible to filter the number of nodes running impact analysis by a percentage of the total nodes affected to reduce bottlenecks for customers with large installs.
Issues resolved in this release:
- Fixed an issue in the node table so that fact charts show the correct number of nodes with filters applied.
Security fixes in this release:
- CVE-2023-36478: CD4PE is not vulnerable to this CVE, but it now runs the updated version of Jetty that addresses this vulnerability.
4.27.1 RELEASE NOTES 5.1.2 RELEASE NOTES DEMO PUPPET
Oct. 11, 2023
This dual release of CD4PE removes barriers to efficiency by correcting an issue that could cause jobs to fail in the first stage of the pipeline.
Issues resolved in these releases:
- Corrected an issue in which CD4PE jobs had a chance of failing if run in the first stage of the pipeline (following a series of changes in a previous version that added additional context to the job environment).
Oct. 4, 2023
This release corrects an issue that could cause login errors, improving the user experience for CD4PE users.
Issues resolved in this release:
- Fixed an issue that could create login errors for LDAP users when deleting a workspace.
Sept. 8, 2023
Streamline Puppet code testing even further with a new installation method based on Bolt, fully supported by Puppet. New to CD4PE 5.0.0, the lightweight installer helps users reduce TTV with a familiar workflow, improved supportability and a seamless install process that doesn’t involve Kubernetes administration. With the new CD4PE installer, your team can start using CD4PE faster than ever, keep driving value with a streamlined upgrade path, and save time with easier license management and troubleshooting.
CD4PE 5.x series replaces Puppet Application Manager with Puppet Bolt for installation and management. Users must migrate 4.x series data (including the database, object store, and configuration settings) to the new installation. For migration instructions, visit Docs.
New in this release:
- New Bolt-based installer and administration platform. In the CD4PE 5.x platform, Puppet Bolt, an open-source agentless automation tool fully supported by Puppet, is now used to manage an automated plan for installing CD4PE. The replacement enables a significantly streamlined experience for installation, upgrades, license management, troubleshooting, and more.
Removed in this release:
- Deprecated support for Puppet Application Manager. In CD4PE 5.0.0, Puppet Application Manager has been replaced by Puppet Bolt for installation and management.
Aug. 2023
A series of UI updates in Continuous Delivery for Puppet Enterprise 4.26.0 make it easier to find what you need to test and deliver your Puppet code faster and with greater accuracy. In addition, a security fix addresses a CVE related to the Okio client when handling a GZIP archive to improve the usability and reliability of CD4PE.
New in this release:
- Refreshed the “Control Repos” and “Modules” pages.
- Modernized the UI for easier, more intuitive navigation.
- Large object data store is now using PostgreSQL.
Security fixes:
- Upgraded okio-jvn to version 3.4.0 to address CVE-2023-3635.
When it comes to code delivery, usability is key to saving time and reducing headaches. A new series of UX updates – including message updates and a refresh of some of the most user-facing pages in CD4PE – make it easier than ever for teams to work together to integrate and deliver great Puppet code. Additionally, a slew of issue fixes and security updates make sure you can keep working in CD4PE with confidence.
New in this release:
- Refreshed the “Create Account” and “Forgot Password” pages in CD4PE.
- Modernized the UI for easier, more intuitive navigation.
Issues resolved in this release:
- CD4PE default pipeline impact analysis fails with a non-actionable error message: Updated the error message to make it more descriptive and useful when a pipeline with no deployment stage fails the impact analysis stage.
- GetJobInstanceV1 returns control repo display name for GitLab: Fixed an issue where links to a GitLab source control repository from the Job details screen wouldn't work if the control repo/module name did not match the GitLab repo name.
Security fixes:
- Upgraded gin-gonic to version 1.9.1 to address CVE-2023-29401.
- Upgraded guava to version 32.0.0-android to address CVE-2023-2976.