Blog
August 3, 2022

Get an overview and examples of Puppet functions in this blog, including:
Back to top
What Are Puppet Functions?
Puppet functions are pieces of code that are executed during catalog compilation.
Let me direct you to an in-depth version of this post on Dev.to that goes into more background detail on Puppet functions and explains the why a bit more, in case you need that refresher before moving onto the rest of the post below.
Back to top👉 When accurate data is important — you need to get your fact(ers) together. Watch the webinar now >>
Agent-Side Functions in Puppet 6
Puppet 6 introduced Deferred functions, a new feature that allows you to run code on the agent side during enforcement. This is both functionality that people have been requesting for ages and also behavior that many people already mistakenly assumed existed. As a matter of fact, the Puppet execution model isn't very well understood at all and many people already think they're using Puppet like a shell script engine!
So first, let's take a quick look at how the catalog gets built and enforced. There are a few stages we need to understand.
- The agent generates facts about itself and sends them to the server.
- The server uses these facts, the Hiera data, and the Puppet codebase to build a catalog — the state model that describes how the agent should be configured.
- The agent then enforces that configuration and sends a report back to the server describing any changes that were made.
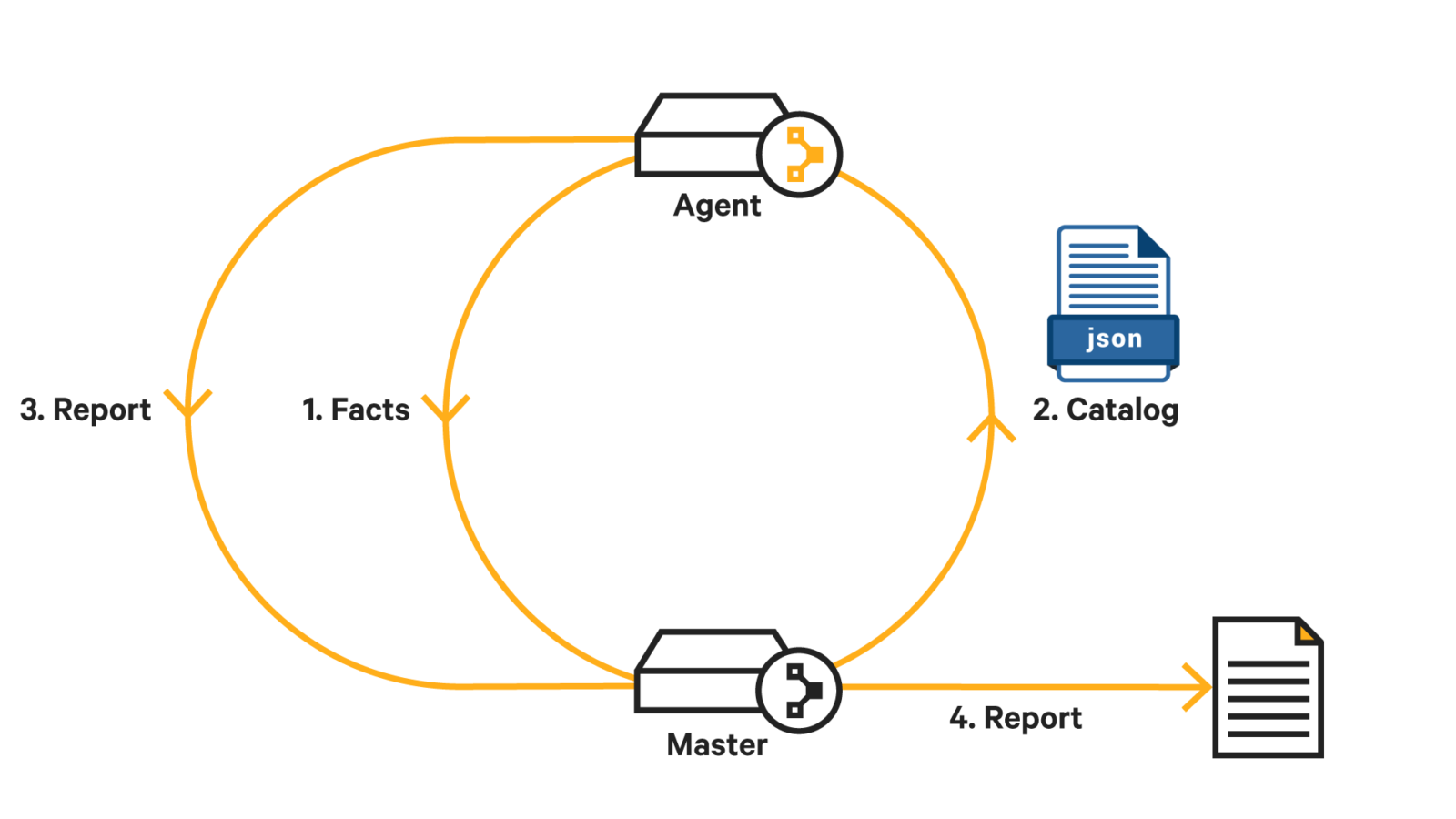
The key point to understand about this model is that only static data is exchanged between the server and the agent. For example, the catalog is a static JSON document that simply lists out resources that should exist and the properties they should have. See the simplified example below (note that some elements have been omitted for readability).
$ jq '.resources[] | select(.type == "Service" and .title == "pxp-agent")' catalog.json
{
"type": "Service",
"title": "pxp-agent",
"parameters": {
"ensure": "running",
"enable": true
}
}There's no way to tell what code or logic was used to generate this, and there's no way to make conditional decisions based on this resource other than just standard resource relationships. For example, you cannot run an exec command to perform some kind of initialization process if a service resource fails to start properly. Functions that ran during compilation don't show up in the catalog at all!
People often want to use exec resources to generate values or for conditional logic. But as you can see here, they're just another resource with parameters that describe their desired state. The results aren't known at compile time, so they cannot be used in conditional statements in your Puppet code.
$ jq '.resources[] | select(.type == "Exec" and .title == "tunnelblick autoupdate")' catalog.json
{
"type": "Exec",
"title": "tunnelblick autoupdate",
"parameters": {
"command": "defaults write net.tunnelblick.tunnelblick updateCheckAutomatically -bool 'true'",
"path": "/usr/bin",
"user": "ben",
"unless": "defaults read net.tunnelblick.tunnelblick updateCheckAutomatically | grep -q '1'"
}
}This is designed for consistency and predictability. By looking at the catalog, you know that after it's been enforced that the pxp-agent service will be running and will start on bootup. Shell scripts, or other evaluated code, don't have this property. Instead, the end state depends on a monumentally complex intersection of preconditions and assumptions. In a nutshell, having provable end states is why many auditors accept Puppet catalogs and/or reports as valid proof of compliance.
So why would we want to build in the ability to run functions on the agent during enforcement? Didn't we just say that lacking this ability makes the catalogs more provable? That would be true if we were talking about unchecked agent-side execution. We're not, however. There are tight constraints on what you can do with Deferred functions.
Known unknowns
Let's talk about values that aren't known at compile time. They're resolved at runtime. This might sound a little concerning, but we already do this all the time. Think about typing puppet.com into your web browser. Your OS actually resolves that to an IP address (and then the physical hardware eventually resolves it even further!). Or think about using your package manager to yum install nginx without knowing exactly which version that would resolve to. Or maybe you wanted to grab a password from the Vault server and write it into a config file without the Puppet server also having access to it….
See, that was a bit of foreshadowing. Up until Puppet 6, there wasn't really a good way to do that. For Puppet to manage a file, it had to know the contents of that file when the catalog was compiled. In other words, your Puppet server needed access to all the secrets of your entire infrastructure. Since anyone with commit privileges can write code to access and potentially leak those secrets, it also meant that you needed very tight constraints on code reviews.
This is the first and most essential use case for a Deferred function: to resolve a value at runtime that the server cannot or should not have access to for whatever reason.
The second use case is for describing intent. Your job with Puppet is to create immutable configuration that is as expressive as possible. Puppet converges your node to the state you describe each time it runs, and it's up to you to make that state as descriptive as possible. Just like the IP address of 216.58.217.46 isn't very descriptive in comparison to the human-readable label of google.com, writing code that shows how an API token is resolved from the Vault server is infinitely more readable than a random string of characters.
Some examples of resolving data at runtime could include:
- Decrypting ciphertext during catalog application.
- Service discovery between nodes at runtime.
- Retrieving API tokens to be used by other resources during catalog application.
In short, you should use deferred functions as named placeholders for runtime data when that makes sense because the label describes intent more than the value it resolves to.
Deferring a function to runtime
After all that conversation, this might be a bit anticlimactic because they're so easy to use. Any Puppet 4.x function that returns a value and doesn't do anything funky with scope or with the catalog internals can be deferred. Here's an example of building a templated file on the agent by deferring two functions, the Vault password lookup and the epp template compilation.
$variables = {
'password' => Deferred('vault_lookup::lookup',
["secret/test", 'https://vault.docker:8200']),
}
# compile the template source into the catalog
file { '/etc/secrets.conf':
ensure => file,
content => Deferred('inline_epp',
['PASSWORD=<%= $password.unwrap %>', $variables]),
}The Deferred object initialization signature is simple and returns an object that we can assign to a variable, pass to a function, or use like any other Puppet object:
Deferred( <name of function to invoke>, [ array, of, arguments] )This object actually compiles directly into the catalog and its function is invoked as the first part of enforcing a catalog. It will be replaced by whatever it returns, similar to string interpolation. The catalog looks something like the JSON hash below. First the password key is replaced with the results of the vault_lookup::lookup invocation, then the content key is replaced with the results of the inline_epp invocation, and then Puppet can manage the contents of the file without the server ever knowing the secret.
$ jq '.resources[] | select(.type == "File" and .title == "/etc/secrets.conf")' catalog.json
{
"type": "File",
"title": "/etc/secrets.conf",
"parameters": {
"ensure": "file",
"owner": "root",
"group": "root",
"mode": "0600",
"content": {
"__ptype": "Deferred",
"name": "inline_epp",
"arguments": [
"PASSWORD=$password\n",
{
"password": {
"__ptype": "Deferred",
"name": "vault_lookup::lookup",
"arguments": ["secret/test", "https://vault.docker:8200"]
}
}
]
},
"backup": false
}
}In short, agent side functions are totally a thing now, with certain guardrails. Any Puppet 4.x function can be deferred as long as it resolves to a value and doesn't muck with catalog internals. It should have no side effects, and you should use deferred functions as named placeholders for late-resolved values. And as always, focus on providing intent rather than being clever.
Learn More
- See my CfgMgmtCamp presentation on Deferred functions.
- Read the docs for writing a Puppet 4.x function.
- Read the docs for deferring a function.
- How to refactor legacy Ruby functions for Puppet’s new API.
Updated Modules For Puppet Functions in Puppet 7.17
In Puppet's first implementation, the catalog was effectively pre-processed to resolve deferred functions into values. This means that before the catalog was enforced, the agent would scan through it and invoke each deferred function. The value returned would be inserted into the catalog in place of the function. Then the catalog would be enforced as usual.
The problem with this approach is that if the function depended on any tooling installed as part of the Puppet run, then it would fail on the first run because it was invoked prior to installation. If the function didn't gracefully handle missing tooling, it could even prevent the catalog from being enforced at all.
As of Puppet 7.17, functions can now be lazily evaluated with the new preprocess_deferred setting. This instructs the agent to resolve deferred functions during enforcement instead of before. In other words, if you use standard Puppet relationships to ensure that tooling is managed prior to classes or resources that use the deferred functions using that tooling, then it will operate as expected and the function will execute properly.
Puppet 7.17 also improves the way typed class parameters are checked. The data type of a deferred function is Deferred, and older versions of Puppet would actually use that type when checking class signatures.
As of Puppet 7.17, deferred functions are introspected and the return type they declare will be used for type matching. If the function doesn't explicitly declare a return type, Puppet will print a warning, but the compilation will succeed. No code changes are required to take advantage of this improvement, but if you're writing classes that might be used with older Puppet versions, you might consider using a variant datatype.
The third, and probably most challenging, concern is that depending on how authors write their modules, you may or may not be able to pass deferred functions as parameters to many popular Forge modules. Let's look at some examples and learn how to anticipate them and future proof our own modules for deferred functions.
There are four major causes of incompatibility, and probably other variations that follow similar patterns. We'll start with the simplest and work towards the most complex.
Problem #1: Puppet language functions cannot be deferred
As of Puppet 4.2, many functions can be written directly in the Puppet language rather than in Ruby. Functions like this are often used to transform data, such as this example from docs that turns an ACL list into a resource hash to be used with the create_resources() function.
Because these functions are not pluginsynced to the agent, they cannot be deferred. In general, this isn't much of a concern because operations like connecting to a Vault server cannot be done easily in the Puppet language anyway. But if you do have such a need, then this function needs to be rewritten in the Ruby language.
Problem #2: strings and resource titles cannot be deferred
A value that comes from a deferred function cannot be used in a resource title or interpolated into a string. For example, let's say that you added debugging code to a myappstack profile to see what password the Vault server was returning.
class profile::myappstack( String db_adapter, String db_address, String db_password, ) { notify { "Password: ${db_password}": } #... }Instead of the password you expect to see, it's the text form of the Deferred function!
$ puppet agent -t … Notice: Password: Deferred({'name' =>'vault_lookup::lookup', 'arguments' => ['appstack/dbpass', 'https://vault.example.com']})And if you wrote it without string interpolation, like notify { $db_password: }, then it would fail compilation completely and give you a seemingly nonsensical error that might give seasoned C++ programmers template flashbacks.
Error: Evaluation Error: Illegal title type at index 0. Expected String, got Object[{name => 'Deferred', attributes => {'name' => Pattern[/\A[$]?[a-z][a-z0-9_]*(?:::[a-z][a-z0-9_]*)*\z/], 'arguments' => {type => Optional[Array], value => undef}}}] (file: /Users/ben.ford/tmp/deferred.pp, line: 6, column: 12) on node arachne.localThe solution to this problem is that variables you expect to be deferred should not be used as resource titles or in interpolated strings. The notify in this example should be refactored like so:
notify { 'vault server debugging': # We cannot interpolate a string with a deferred value # because that interpolation happens during compilation. message => $db_password, }If you need to interpolate a deferred value into a string, you can do that by deferring the sprintf() function. For example, you could write that notify like so:
notify { 'vault server debugging': # Defer interpolation to runtime after the value is resolved. message => Deferred( 'sprintf', ['Password: %s', $db_password] ), }Don't forget to remove this message once the Vault problem has been resolved so it doesn't leak your secrets!
Problem #3: function arguments can (usually) not be deferred
Closely related to the first problem, function arguments cannot be deferred, unless the function is designed for it. Functions are evaluated during compilation, so if you defer an argument, they'll operate on a Ruby object instead of the resolved value. This is usually noticed when trying to render templated files. For example, if that myappstack profile managed a configuration file with a template, it would include the same text form of the deferred vault lookup function as above:
$ cat /etc/myappstack/db.conf dbpassword = Deferred({'name' =>'vault_lookup::lookup', 'arguments' => ['appstack/dbpass', 'appstack/dbpass']})
In order to properly handle deferred functions, the function using them must also be deferred. For example, you could defer the rendering of the database configuration file using the new deferrable_epp() function that defers template rendering when needed. Using that function to generate templated files allows you to transparently handle deferred parameters. This function is available starting in puppetlabs-stdlib version 8.4.0. Note that it requires you to explicitly pass in the variables you'll be using in the template.
If you need to support earlier versions of stdlib, then you'll need to write the boilerplate logic yourself, which might look something like this:
$variables = { 'password' => $db_password }
if $db_password.is_a(Deferred) { $content = Deferred( 'inline_epp', [find_template('profiles/myappstack.db.epp').file, $variables], ) } else { $content = epp('profiles/myappstack.db.epp', $variables) }
file { '/path/to/configfile': ensure => file, content => $content, }Problem #4: deferred values cannot be used for logic
A value that's not known until runtime cannot be used to make conditional decisions, since all logic is resolved during compilation. An example of this is the puppetlabs-postgresql module, which handles provided password hashes differently based on the algorithm used to create them. If the user expects that password hash to be provided at runtime by a secret server, then it's not known at runtime and the compiler can't choose the appropriate codepath.
The resolution for this kind of problem is to refactor so these decisions don't need to be made during compilation, or so that different data is used to make decisions. In the case of our PostgreSQL module, we refactored that code so that the complete codepaths affected by that conditional were all deferred. The same code will run, but it will all be evaluated during runtime on the agent.
Depending on the type of decision to be made, you could also refactor into using facts, which are evaluated on the agent prior to catalog compilation and then making conditional decisions based on the resolved values of the facts.
Summary
I'm sure you see a common thread in each of these problem scenarios. Values calculated by deferred functions are simply not known at compile time. This means that nothing processed during compilation can use them. You cannot use a deferred value to interpolate into a string, or use it as a key for a selector, or make a logical decision. You cannot render it directly into a templated file; instead you need to include the template source in the catalog and compile it at runtime.
Effectively, a deferred function is only useful when passing the value it generates directly to a parameter of a declared resource, and modules need to be written to take this into account. Module authors should anticipate that people might want to defer certain parameters, such as passwords or tokens or other secret values, and handle those cases by refactoring any use of these values out of compile time and into runtime.
Ecosystem updates that simplify Deferred use cases:
- Set
preprocess_deferredwhen your functions depend on tooling installed by the Puppet run. - Deferred functions are interpolated so that their return types can be used to match data types required by class signatures.
- The new
deferrable_epp()function will automatically defer epp template rendering when appropriate.
Good luck! We're always excited to see the cool things you build.
Back to topGet Started With Puppet Functions
See for yourself what you can do with Puppet functions. Get started with your free trial today.
Learn More
- Find out how Puppet works with Vault by HashiCorp
- Read also: How to Enhance Your Vault Secrets Management Strategy With Puppet
- Check out the podcast episode on debugging Puppet code