Supported architectures
Sections
There are several configurations available for Puppet Enterprise. The configuration you use depends on the number of nodes in your environment and the resources required to serve agent catalogs. When you install PE using the PE installer tarball, you begin with the standard configuration, and can then scale up by adding additional infrastructure components as needed. Alternatively, by using Puppet Installation Manager (beta) to install PE, you can start out with a standard, large, or extra-large configuration.
Existing customer deployments in the field might use other configurations, but for the best performance, scalability, and support, we recommend using one of our three defined architectures unless specifically advised otherwise by Puppet Support personnel. For legacy architectures, we document only upgrade procedures – not installation instructions – in order to support existing customers.
| Configuration | Description | Node limit |
|---|---|---|
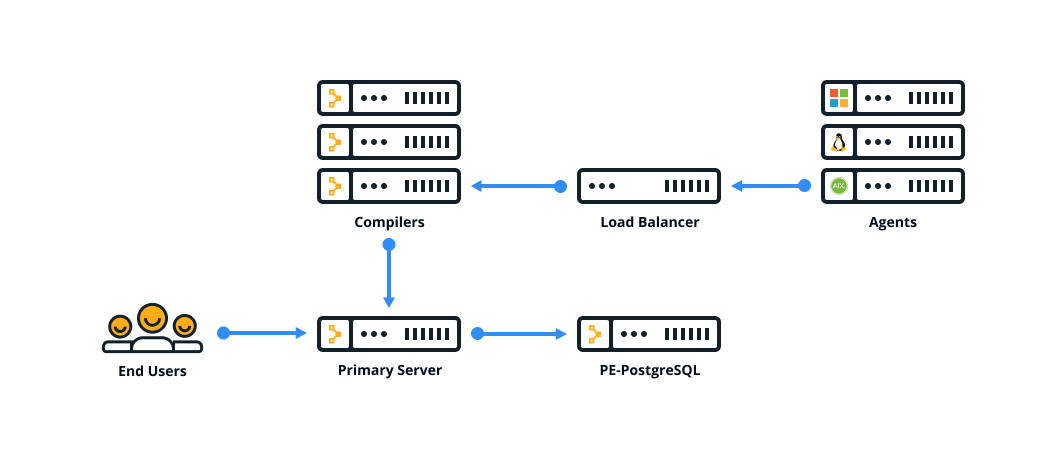
| Standard installation (Recommended) | All infrastructure components are installed on the primary server. This installation type is the easiest to install, upgrade, and troubleshoot. | Up to 2,000 |
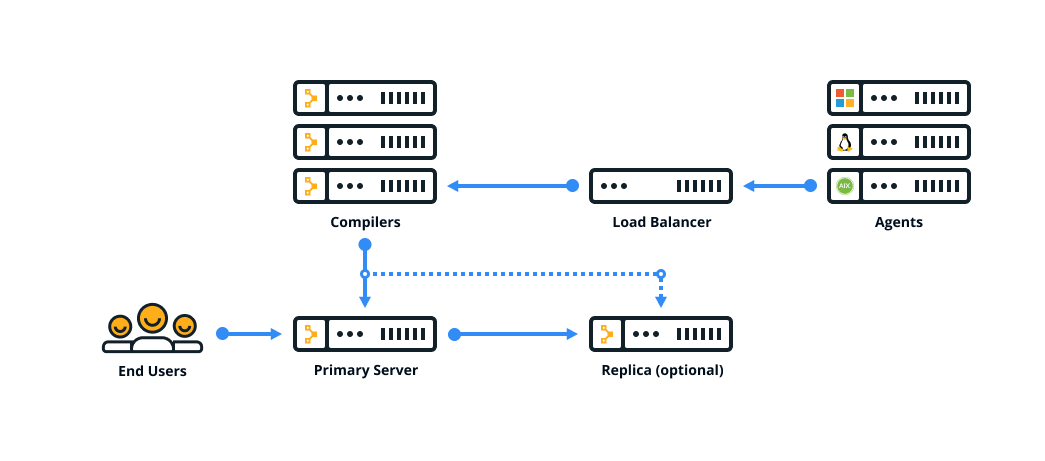
| Large installation | Similar to a standard installation, plus one or more compilers and a load balancer which help distribute the agent catalog compilation workload. | 2,000–20,000 |
| Extra-large installation | Similar to a large installation, plus a database server hosting a PE-PostgreSQL instance for the PuppetDB database. | 20,000+ |
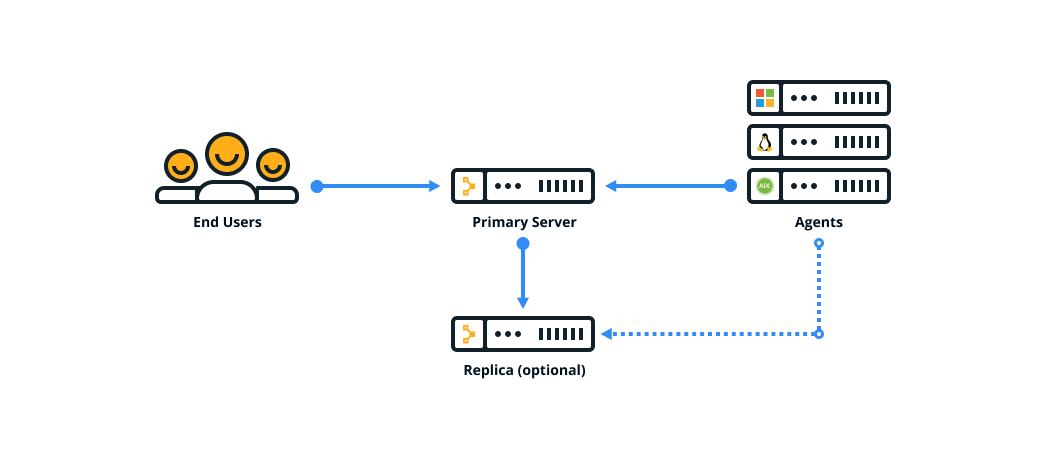
Standard installation
Large installation
Extra-large installation
The extra-large architecture scales PE deployments to 20,000+ nodes. This architecture is intended to be deployed with the help of Puppet solutions experts. For more information about the capabilities of this architecture and how to deploy it, reach out to your technical account manager or Puppet Professional Services.
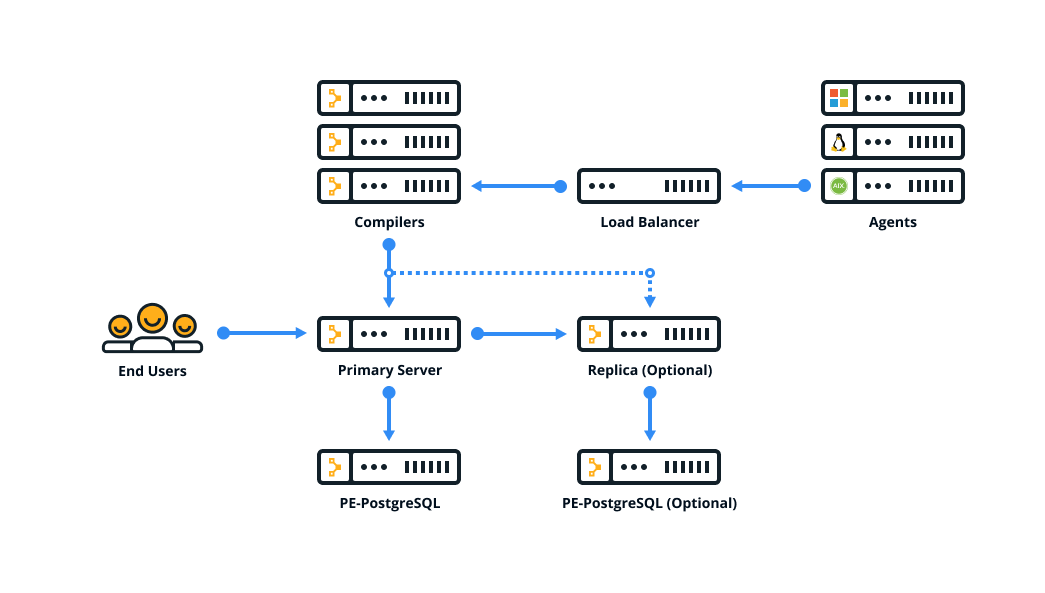
Standalone PE-PostgreSQL (legacy)
Upgrading from the retired split architecture results in a standalone PE-PostgreSQL architecture. This architecture is similar to a large installation, but with a separate node that hosts the PE-PostgreSQL instance. Standalone PE-PostgreSQL can't be configured with disaster recovery.