Integration with External Data Providers
- Product and version: Puppet Enterprise 2019.8
- Document version: 1.0
- Release date: 20 December 2021
Introduction
Puppet is commonly implemented alongside new or existing asset management systems, or CMDBs, which are used to store business and technical information about an organization's IT assets. Puppet can integrate with these sources of data to provide trusted fact values, configure classification, manage self-service Hiera data configuration value lookups, and more, consuming the asset information directly and automatically.
This document describes recommended integration points that Puppet can use to consume data from external systems, or to publish data to external systems. It further describes a standard recommended design pattern for creating and using those integrations, called the Puppet Data Service (PDS) pattern.
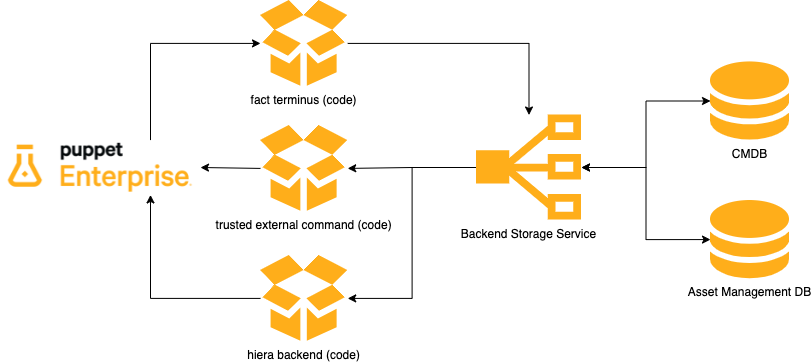
In general, the PDS pattern requires:
A Backend Storage service holding relevant asset information. This can be a dedicated database, or if the originating service is sufficiently performant, Puppet can query or submit data to the originating service directly.
The following recommended integration points are what let Puppet consume from or publish data to the backend service in different ways. Each component is optional, and does not depend on any others:
An external command script, for consuming external data as trusted facts
A Hiera backend function, for consuming Hiera data from the external service
A fact terminus, for publishing node fact updates to an external service
These components are each described in more detail below.
Why Integrate?
Enable self-service scenarios
Provide (inject) trusted facts which can be changed
Provide a way to change classification and configuration externally to the PE console or hiera
Use existing data (an established source of truth) as configuration data (hieradata or facts)
Consistent usage of Puppet generated metadata in other automation systems
Backend Storage Service
The key component of integrating with external data sources is the Backend Storage Service (BSS). This component stores all configuration data and provides this data to Puppet.
Requirements
Any data storage solution can act as the BSS provided it complies with the following requirements:
The BSS should be highly available and resilient
The BSS should be able to handle a load of
2 + Nread queries per Puppet agent run, where N is the number of Hiera layers which consult the external source. For example: given a Hiera hierarchy with three (3) external layers, 1000 Puppet agents, and a 30-minute run interval (1800 seconds), the BSS should be able to handle((2 + 3) * 1000 queries) / 1800 sec = 2.7 queries/sec.
Because of the requirements above, a system of record such as a CMDB or an asset management database is not always fit to act directly as Puppet's BSS. As the diagram above outlines, the recommended architecture in that circumstance is to create a performant BSS (database) specifically for use by Puppet, and "feed" that dedicated BSS from those systems of record, triggering BSS updates on system-of-record changes.
Some systems which support other automation solutions may already be designed to support a workload similar to that required by Puppet, making them capable of serving as a BSS. For example, Red Hat Satellite.
Trusted External Command
Trusted external commands let you consume data from arbitrary sources or APIs, and make it available to Puppet underneath each node's trusted.external fact key.
When integrating with an external data provider, you can inject any information the BSS provides about a node—information such as asset owner, intended purpose, SDLC environment, etc—into Puppet using a trusted external command. The Trusted External Command is an API inside Puppet which establishes a way to provide trusted node data from external sources.
Trusted External Command is configured in /etc/puppetlabs/puppet/puppet.conf as follows:
trusted_external_command = "/etc/puppetlabs/puppet/trusted-external-commands/"This setting should point to a directory which will contain one or more executable scripts. E.g.
/etc/puppetlabs/puppet/trusted-external-commands/bssWhen executed with a single command-line argument—the name of a Puppet certificate—these executables should print to stdout a JSON object containing information about the named node. Each key in the JSON object will be made available to Puppet underneath trusted.external, and the script's name. E.g., if the bss script returns {"one": 1, "two": 2}, the one key's value will be available as trusted.external.bss.one.
After changing this configuration, the pe-puppetserver service needs to be restarted.
Hiera Backend
Hiera backends permit you to consume data from arbitrary sources or APIs, and consult that data when resolving Hiera data lookups.
A Hiera backend is a function written in Ruby or Puppet DSL which translates a Hiera lookup into a query to the Backend Storage Service. The Hiera backend is an implementation of the Puppet Hiera Backend API.
A Hiera backend function is specific to the BSS chosen.
The data_hash Hiera backend type is usually the best option when integrating with an external data provider. Other backend types exist: lookup_key and data_dig. Reasons for choosing these additional types are unusual, and beyond the scope of this document.
The Hiera backend should perform one read query per Puppet run, per configured Hiera hierarchy layer which uses the external backend. The approximate load can be calculated as queries/sec = (N * L) / R. Where N = number of nodes, L = number of Hiera layers configured to use the backend, and R = the Puppet agent run interval in seconds.
Fact Terminus
Fact terminus integrations permit you to publish Facter information to external systems, triggering every time a node submits a fact data update.
Fact termini can be distributed via regular Puppet Modules and used to augment functionality throughout Puppet. Puppet has several termini types; fact routing is just one of many things implemented by termini.
In generic terms, a terminus is an interface which implements a set of methods for saving and retrieving data from some backend. Puppet’s own Splunk integration builds upon the default YAML terminus to forward facts over Splunk’s HTTP Event Collector.
Once you’ve developed a custom terminus for storing facts in your external system and distributed via a module, you may reconfigure Puppet’s Advanced Plugin Routing via routes.yaml.
Example: Puppet’s Splunk integration